Fast, Frictionless, and Secure: Explore our 120+ Connectors Portfolio | Join Webinar!
Apache Kafka Meets Table Football
Get started with Confluent, for free
Watch demo: Kafka streaming in 10 minutes
What happens when you let engineers go wild building an application to track the score of a table football game? This blog post shares SPOUD’s story of engineering a simple application with Apache Kafka®, ksqlDB, and Red Hat’s Quarkus. Spoiler alert: It was a blast!
Introduction
We are SPOUD, a small company based in Bern, the capital of Switzerland. We’re specialised in event-driven architectures, real-time decision-making, and streaming technologies, especially Kafka. Similar to other startups with spare office space, we created a small playground in the office to play table football. Being the geeks we are, we always find ways to make simple things look fancy, which is why we created “Töggelomat” (in Swiss German, “töggele” means “table football”), an application that keeps track of game scores and matches players according to their skills. Unfortunately, due to COVID-19, we don’t play as much as we used to.
Goal
We initially decided to make Töggelomat a reality at last year’s SPOUD hackathon. As stated earlier, we use Kafka a lot and have expertise in running clusters, connecting to data with Kafka Connect, and using AI together with stream processing. However, we hadn’t gotten the chance to really use ksqlDB, and we wanted to try it out with Quarkus.
Let’s play
As we now dive deep into the technical details behind building Töggelomat, you can look at our GitHub project for the source code. Note: the ksqlDB queries are very interesting.
First, we needed to think in terms of events versus static databases because everything is an event. Using the event sourcing technique, we created a topic with a list of current employees.
Then, using ksqlDB queries, we created players with a starting score of 500 points.
INSERT INTO toeggelomat_player
SELECT
uuid,
nickName,
email,
500 as defensePoints,
500 as offensePoints
FROM employee;
With the query above, the toeggelomat_player compacted topic is filled every time a new employee is added to the topic employee.
To generate a new match, the Töggelomat application reads the last state from the toeggelomat_player topic and randomizes a fair match. Once the players are chosen, the application generates a new match and displays it in the front end. When the match is done, the score is entered in the UI and the application publishes the topic toeggelomat_match_result. The topic is visible in SPOUD’s data platform product, Agoora, and displays the description of the topic, the inferred schema, and the profile with some example data. Feel free to register and try it out for yourself.
After a match result, we need to compute the score, which is based on the skills of the players. If two higher-ranked players win against two lower-ranked players, they will not earn a lot of points. In reverse, if the lower-ranked players win, they will be generously rewarded. The point computation is done in the application, and the score is published on the topic toeggelomat_scores.
With ksqlDB, we create four entries (one for each player) in the topic toeggelomat_point_change based on the score published in the topic toeggelomat_scores. The point changes are then applied to the topic toeggelomat_player, to close the loop.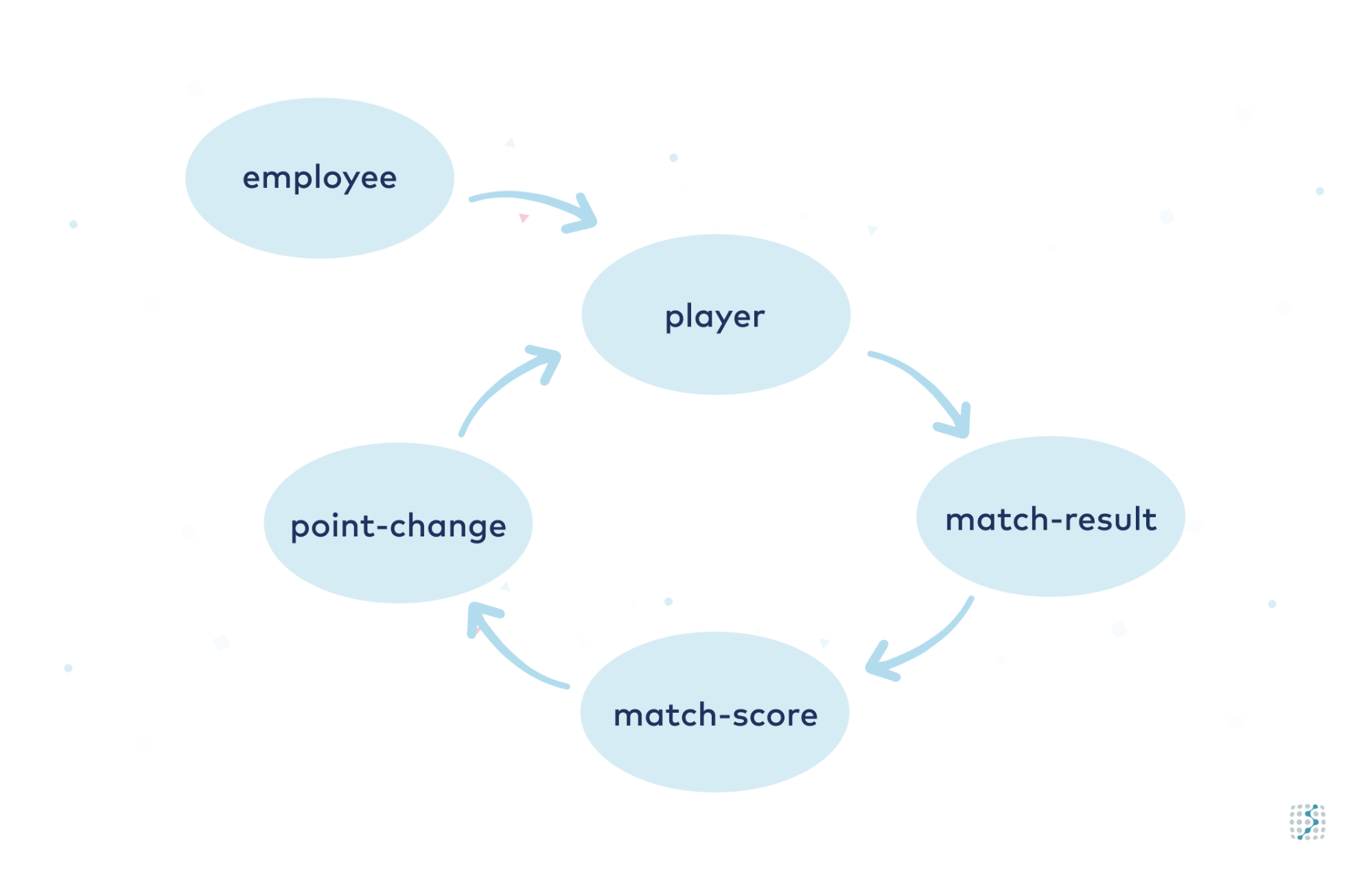 In summary:
In summary:
- Employees are converted to Töggelomat players
- At the end of a match, the result is written
- Scores are calculated from the result
- Match scores produce point changes for each player
- Point changes are applied to the players
Result
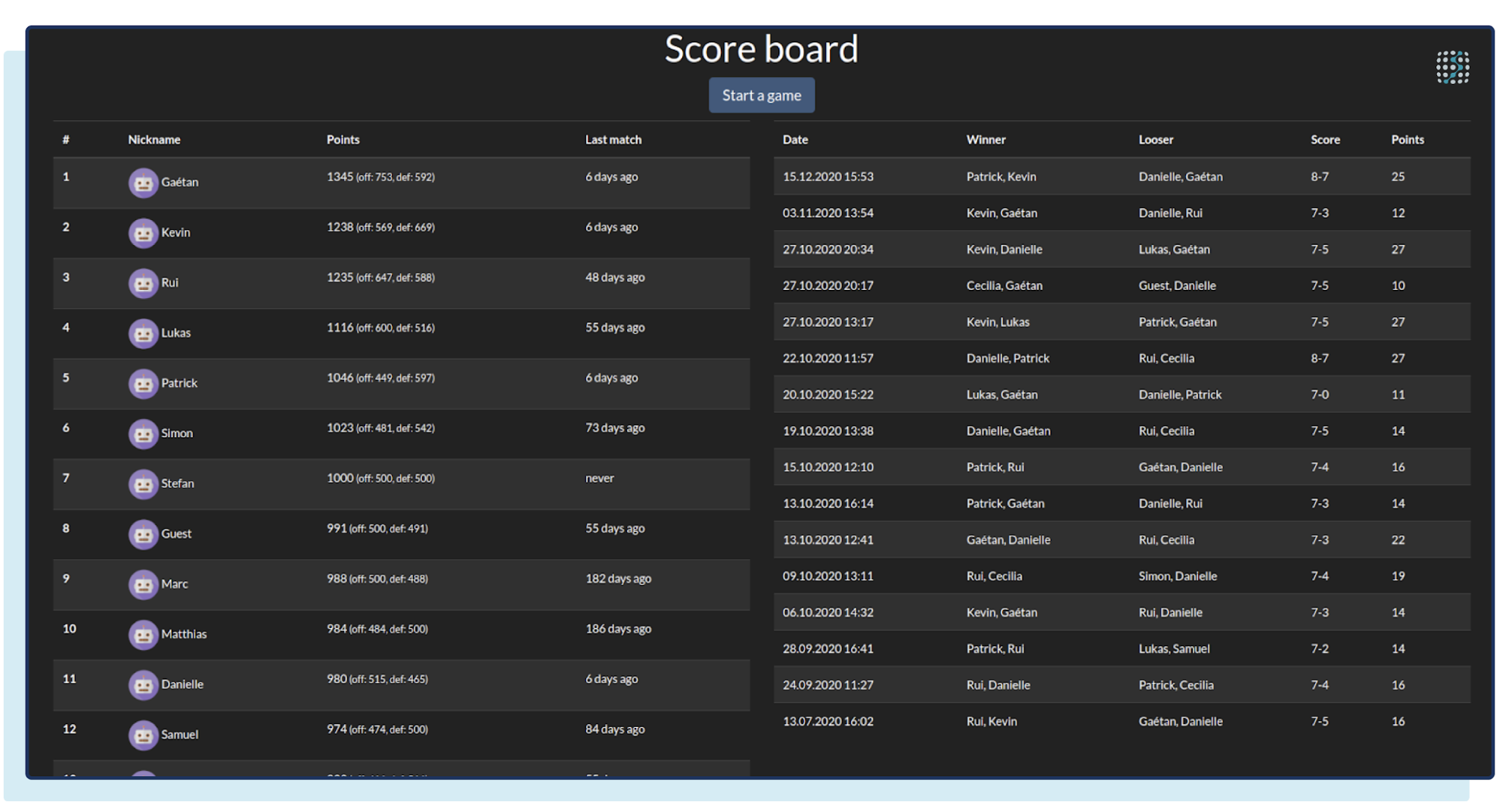
After two hackathon days and a few beers, the results looked like this, with the main page of the application showing the rank of each player:
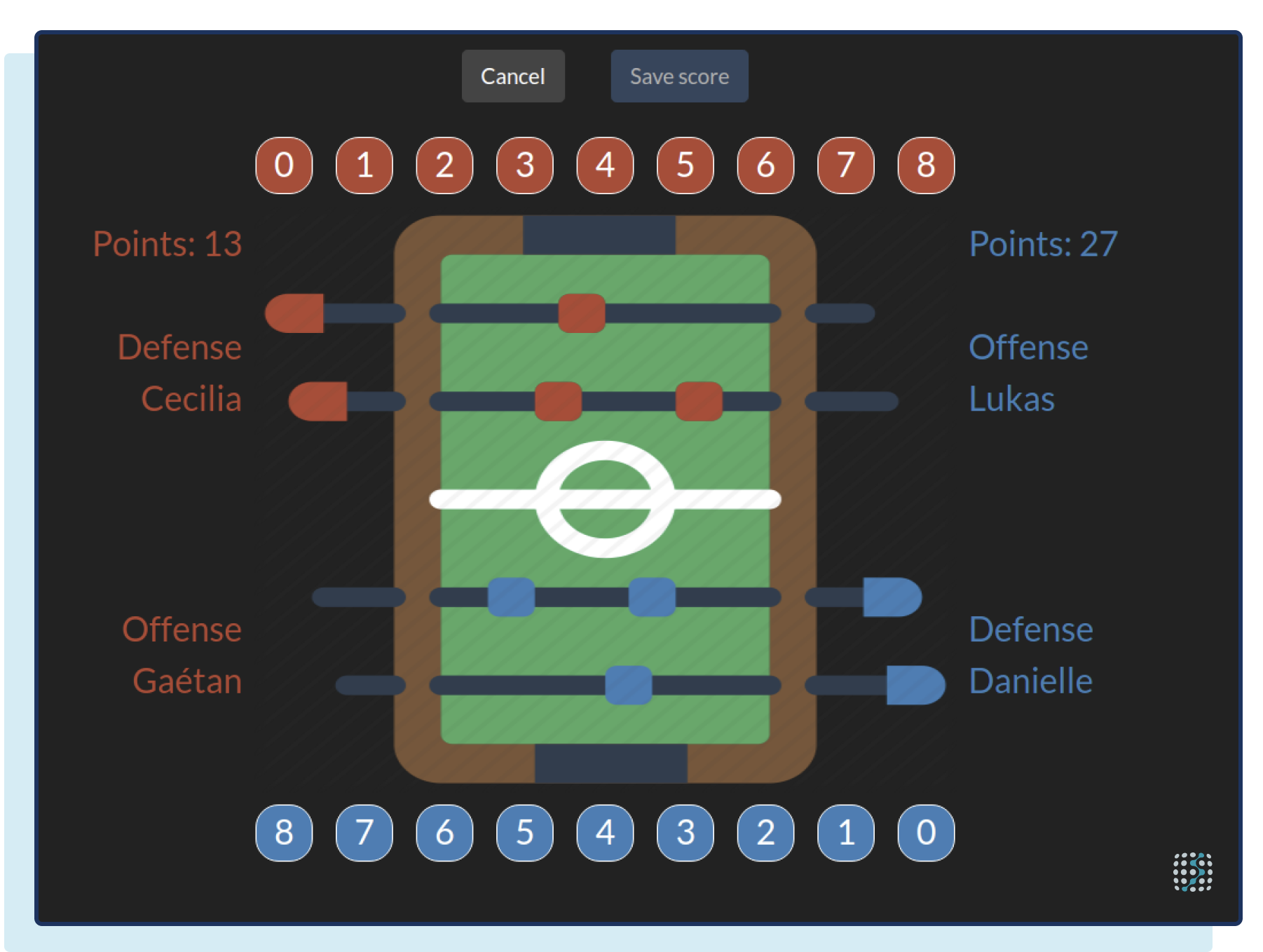
Then players are selected and a random match is generated.
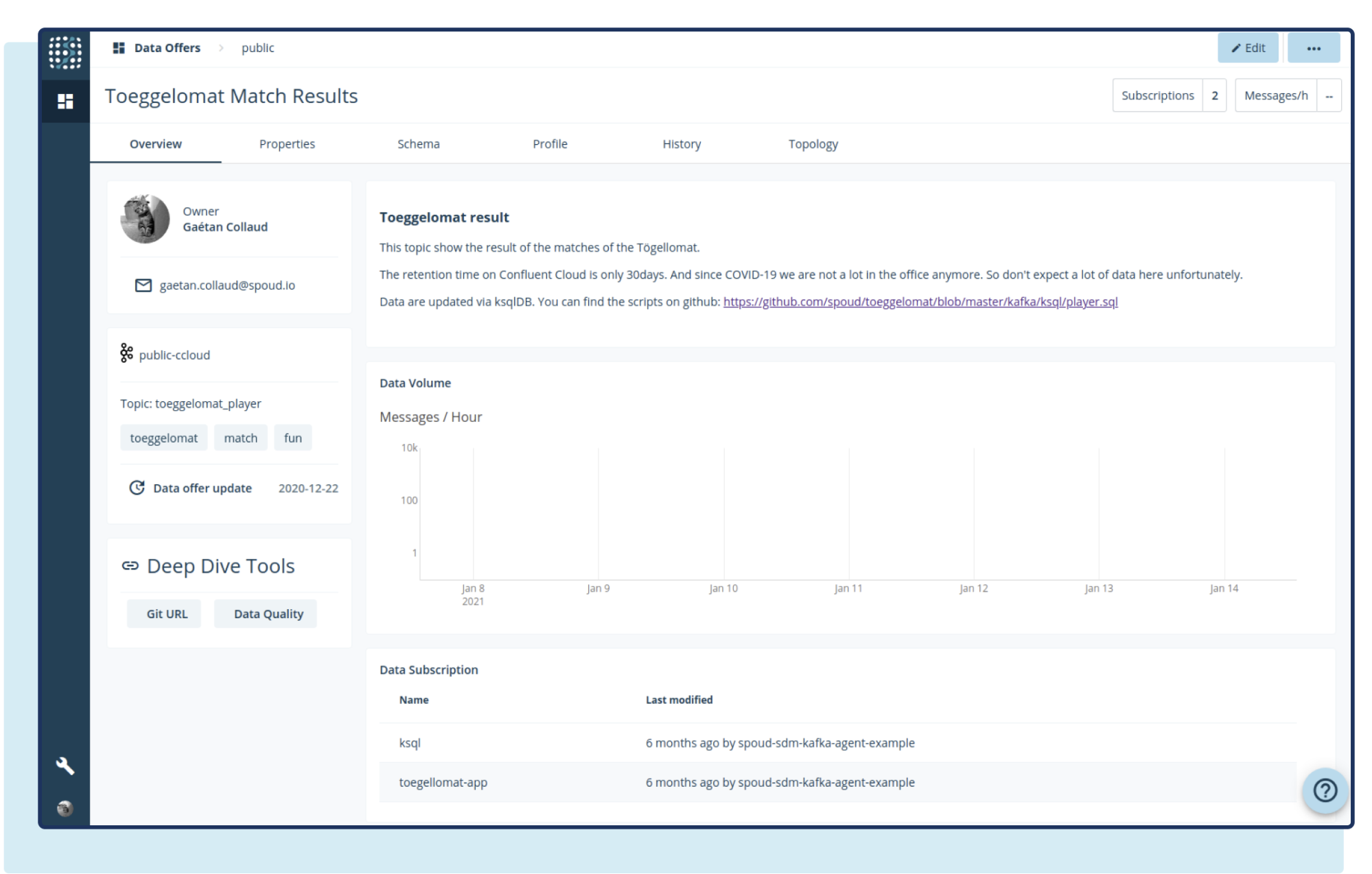
We expose the data as an “offer,” similar to what we call them in Agoora. The offer has a description as well as the data schema and profile. The profile is useful to data scientists who want to look more closely at the data.
Conclusion
It’s honestly overkill to use so many topics for such a small use case, but the main point was to learn something, and we did! First of all, Quarkus is awesome and could really be the next Spring Boot. It’s a perfect match for Kafka and the cloud in general. Its reactive nature really helps when writing an event-driven application. Plus, its startup time and low memory footprint are better than that of a standard Java application.
Ever since the hackathon, SPOUD has been integrating Quarkus more and more. KsqlDB is also really great and easy to use. It gives you the sense of a database management system (DBMS), but you are in fact working with event streams.
At the same time, you can even join streams! Isn’t that awesome? Think about all the possibilities! Yet, our use case also highlighted some pain points. For example, there is a loop, the match score is dependent on the player’s ranking, and the ranking is also influenced by the score. In a DBMS, you have a defined state at any moment, and all changes in the state are ensured by transactions. Although this makes ensuring consistency easier, events give you the flexibility to scale. For this particular use case, there is at most one match every five minutes, so the loop has the time to complete before the next match. With time-sensitive use cases, you want to avoid loops as much as possible.
The use case presented in this blog post used Confluent Cloud, which was inexpensive since there wasn’t a lot of data.
| ℹ️ | Sign up for Confluent Cloud and receive $400 to spend within Confluent Cloud during your first 60 days. In addition, you can use the promo code CL60BLOG for an additional $60 of free Confluent Cloud usage.* |
Confluent also allows you to leverage ksqlDB as a service, although in our case the lowest instance available was bigger than what we were looking for. And because an SLA wasn’t essential for our use case, we decided to run our own ksqlDB server based on the documentation and using the Docker image from Confluent.
What’s next?
Now that this project works we can think of what’s next? Here are some additional ideas that we could implement based on the modularity of dedicated topics:
- Real-time game information (e.g., a dashboard on a screen)
- Slack integration
- Achievements
For more information about Töggelomat, check out our Kafka Summit 2020 talk.
Get started with Confluent, for free
Watch demo: Kafka streaming in 10 minutes
Avez-vous aimé cet article de blog ? Partagez-le !
Abonnez-vous au blog Confluent



Confluent’s Customer Zero: Building a Real-Time Alerting System With Confluent Cloud and Slack
Turning events into outcomes at scale is not easy! It starts with knowing what events are actually meaningful to your business or customer’s journey and capturing them. At Confluent, we have a good sense of what these critical events or moments are.


How To Automatically Detect PII for Real-Time Cyber Defense
Our new PII Detection solution enables you to securely utilize your unstructured text by enabling entity-level control. Combined with our suite of data governance tools, you can execute a powerful real-time cyber defense strategy.