Fast, Frictionless, and Secure: Explore our 120+ Connectors Portfolio | Join Webinar!
ksqlDB Meets Java: An IoT-Inspired Demo of the Java Client for ksqlDB
Get started with Confluent, for free
Watch demo: Kafka streaming in 10 minutes
Stream processing applications, including streaming ETL pipelines, materialized caches, and event-driven microservices, are made easy with ksqlDB. Until recently, your options for interacting with ksqlDB were limited to its command-line interface (CLI), user interface (UI), and REST API. The CLI and UI are more convenient and intuitive, while the REST API is more compatible with writing applications. The introduction of ksqlDB clients seeks to deliver the best of both worlds, enabling convenient and intuitive interaction with ksqlDB servers from within your applications. The first such client—the Java client for ksqlDB—shipped with ksqlDB 0.10.0, with additional functionality added in 0.11.0 and 0.12.0. Let’s see it in action.
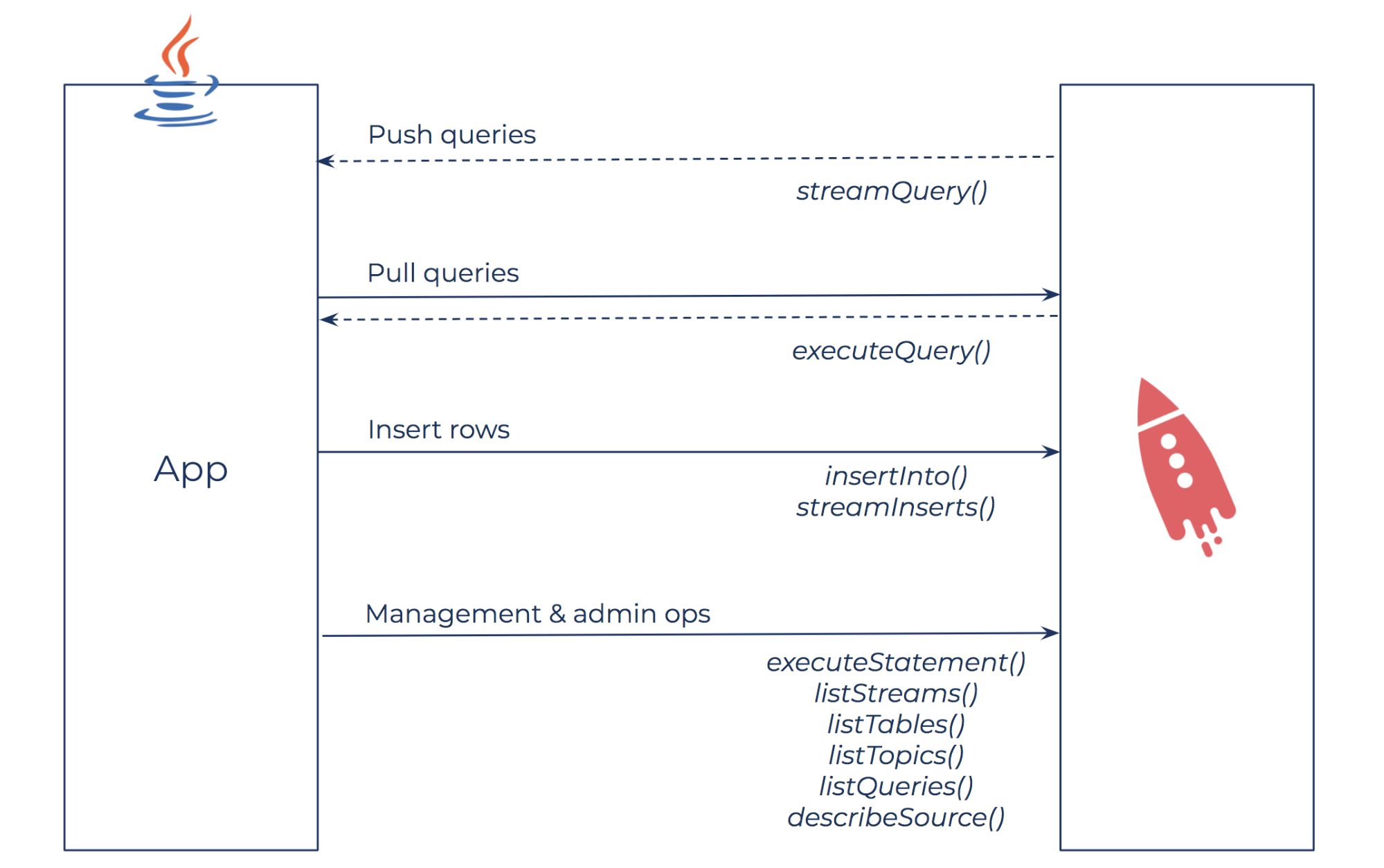 The Java client for ksqlDB supports push and pull queries; inserting rows into existing streams; the creation and deletion of streams, tables, and persistent queries; as well as other admin operations.
The Java client for ksqlDB supports push and pull queries; inserting rows into existing streams; the creation and deletion of streams, tables, and persistent queries; as well as other admin operations.
Follow along with the complete code examples and run a quick demo yourself on GitHub.
An IoT application
Suppose we have an IoT system consisting of various different types of sensors. Sensor readings are produced to Apache Kafka®, and for each sensor type, we’d like to use ksqlDB to create a materialized cache that users and applications may query to retrieve the latest reading(s) for a particular sensor ID (of the relevant type).
Different sensor types may have different schemas for the readings produced by sensors of that type and, as a result, should be modeled as different ksqlDB streams.
| Sensor Type 1: Single-value, stationary sensor |
Schema: (sensorID VARCHAR, reading INTEGER) |
| Sensor Type 2: Multi-value, stationary sensor |
Schema: (sensorID VARCHAR, reading1 DOUBLE, reading2 BIGINT) |
| Sensor Type 3: Single-value, non-stationary sensor |
Schema: (sensorID VARCHAR, reading DOUBLE, latitude DOUBLE, longitude DOUBLE) |
Examples of different sensor types and schemas
We’ll assume that the schemas for all sensor types contain a string-valued field sensorID, representing the ID of the sensor from which a particular reading was recorded.
Let’s use the Java client for ksqlDB to implement a programmatic way to add new sensor types, remove sensor types that are no longer needed, and query materialized views for the latest sensor readings.
Getting started
To get started with the client, create a Java application with the example POM in the documentation and initialize the client to connect to your ksqlDB server:
public class SensorTypesManager {
private Client client;
public SensorTypesManager(String serverHost, int serverPort) {
ClientOptions options = ClientOptions.create()
.setHost(serverHost)
.setPort(serverPort);
this.client = Client.create(options);
}
// ...
}
Adding a new sensor type
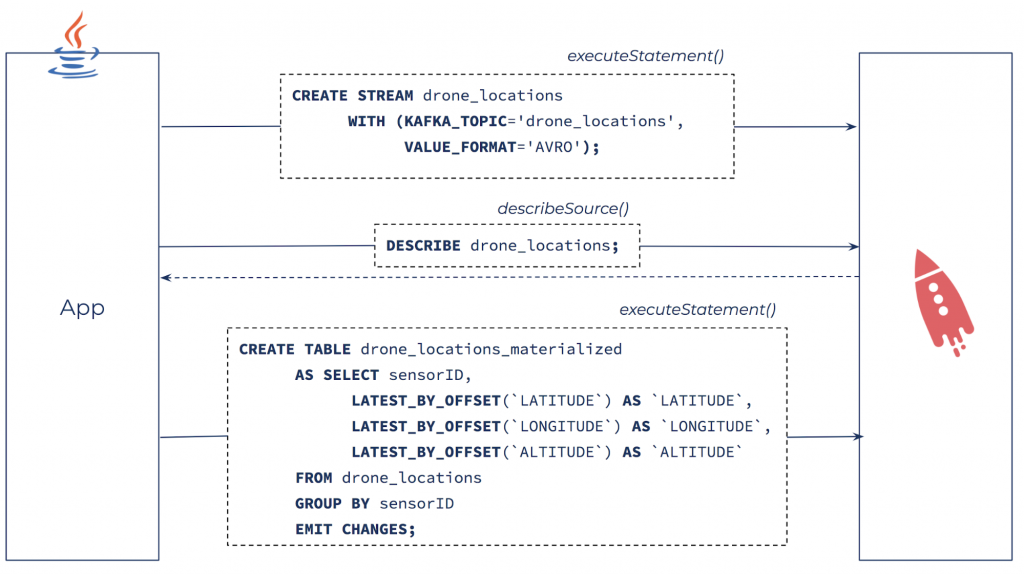 Add a new sensor type by defining a ksqlDB stream and building a materialized view of the latest sensor data.
Add a new sensor type by defining a ksqlDB stream and building a materialized view of the latest sensor data.
To add a new sensor type, we first have to create a ksqlDB stream to represent the sensor readings for sensors of the new type:
public void addSensorType(String sensorType, String sensorReadingsTopic) {
String createStreamSql = "CREATE STREAM " + sensorType
+ " WITH (KAFKA_TOPIC='" + sensorReadingsTopic + "', VALUE_FORMAT='AVRO');";
try {
client.executeStatement(createStreamSql).get();
} catch (ExecutionException | InterruptedException e) {
throw new RuntimeException("Failed to create stream", e);
}
// ...
}
Note that when using Avro data with ksqlDB, it’s not necessary to explicitly specify the schema of new streams as ksqlDB will look up the schema for the relevant Kafka topic in the Confluent Schema Registry. The same is true of Protobuf and, optionally, JSON data as well.
Next, we create a materialized cache containing the latest sensor readings for each sensor of the new type. In order to do this, we need access to the schema of the newly created stream. Our Java program could fetch the schema from Schema Registry directly via its REST API, or we can retrieve the schema by describing the newly created stream in ksqlDB instead. We’re specifically interested in the column names for the new stream so we can include them in the materialized view.
List<String> columnNames;
try {
SourceDescription description = client.describeSource(sensorType).get();
columnNames = description.fields().stream()
.map(FieldInfo::name)
.collect(Collectors.toList());
} catch (ExecutionException | InterruptedException e) {
throw new RuntimeException("Failed to describe stream", e);
}
With the list of column names, we can now create a materialized view of the latest sensor readings per sensor. To do this, we’ll use the LATEST_BY_OFFSET built-in aggregation function to track the latest value for each column. For example, given the sensor type drone_locations with schema (sensorID VARCHAR, latitude DOUBLE, longitude DOUBLE, altitude DOUBLE), the command for creating a materialized view with the latest sensor readings per sensor is this:
CREATE TABLE drone_locations_materialized
AS SELECT sensorID,
LATEST_BY_OFFSET(`LATITUDE`) AS `LATITUDE`,
LATEST_BY_OFFSET(`LONGITUDE`) AS `LONGITUDE`,
LATEST_BY_OFFSET(`ALTITUDE`) AS `ALTITUDE`
FROM drone_locations
GROUP BY sensorID
EMIT CHANGES;
We create this command programmatically and submit it using the Java client:
String tableName = sensorType + "_materialized";
String materializedViewSql = "CREATE TABLE " + tableName
+ " AS SELECT sensorID, "
+ columnNames.stream()
.filter(column -> !column.equalsIgnoreCase("sensorID"))
.map(column -> "LATEST_BY_OFFSET(`" + column + "`) AS `" + column + "`")
.collect(Collectors.joining(", "))
+ " FROM " + sensorType
+ " GROUP BY sensorID"
+ " EMIT CHANGES;";
Map<String, Object> properties = Collections.singletonMap("auto.offset.reset", "earliest");
try {
client.executeStatement(materializedViewSql, properties).get();
} catch (ExecutionException | InterruptedException e) {
throw new RuntimeException("Failed to create materialized view", e);
}
By passing in the query property auto.offset.reset with value earliest, the materialized view will be populated with any sensor readings already present in the source Kafka topic.
Putting it all together, we have our method for adding a new sensor type. Notice how the method is currently synchronous—the method blocks until the requests to create the new stream and materialized view have been acknowledged by the ksqlDB server.
Rather than calling .get() and blocking on each of the CompletableFutures returned by the ksqlDB client methods executeStatement() and describeSource() individually, we can take advantage of the async nature of the client methods by the composing the CompletableFutures. Here’s the same method for adding a new sensor type written to be asynchronous instead:
public CompletableFuture<Void> addSensorType(String sensorType, String sensorReadingsTopic) {
// Create ksqlDB stream
String createStreamSql = "CREATE STREAM " + sensorType
+ " WITH (KAFKA_TOPIC='" + sensorReadingsTopic + "', VALUE_FORMAT='AVRO');";
return client.executeStatement(createStreamSql)
// Describe the newly create stream
.thenCompose(executeStatementResult -> client.describeSource(sensorType))
.thenCompose(sourceDescription -> {
List<String> columnNames = sourceDescription.fields().stream()
.map(FieldInfo::name)
.collect(Collectors.toList());
// Create materialized view
String tableName = sensorType + "_materialized";
String materializedViewSql = "CREATE TABLE " + tableName
+ " AS SELECT sensorID, "
+ columnNames.stream()
.filter(column -> !column.equalsIgnoreCase("sensorID"))
.map(column -> "LATEST_BY_OFFSET(`" + column + "`) AS `" + column + "`")
.collect(Collectors.joining(", "))
+ " FROM " + sensorType
+ " GROUP BY sensorID"
+ " EMIT CHANGES;";
Map<String, Object> properties = Collections.singletonMap("auto.offset.reset", "earliest");
return client.executeStatement(materializedViewSql, properties);
// Simplify return signature by returning null
}).thenApply(executeStatementResult -> null);
}
This new version of the method returns promptly, before any of the requests are issued to the ksqlDB server. The calling code may now decide whether to block until the new sensor type has been added (by calling .get() on the CompletableFuture returned by addSensorType()) or to perform other actions without blocking.
Besides making the code non-blocking, CompletableFuture composition has also allowed us to clean up the error handling necessitated by the .get() calls and is therefore the preferred approach when working with CompletableFutures.
To productionize this code, we’d want to add more intelligent error handling in order to avoid non-transactional, failed attempts to add a new sensor type. For now, this is left as an exercise for the reader 🙂
Removing a sensor type
As old sensor types are phased out of our IoT system, we’d like a programmatic way to tear down the ksqlDB query populating the materialized view for those sensor types, and also to clean up the ksqlDB streams and tables.
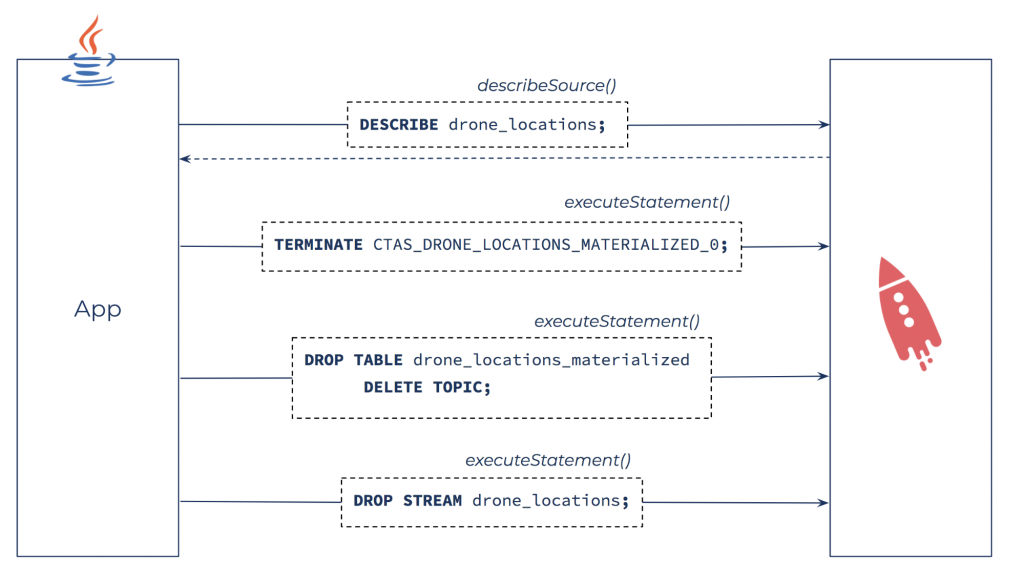 Remove an existing sensor type by cleaning up the source stream, materialized view, and the query that populates the materialized view (in reverse order).
Remove an existing sensor type by cleaning up the source stream, materialized view, and the query that populates the materialized view (in reverse order).
Given the name of the sensorType that we’d like to remove, we first have to find the ID of the query that populates the materialized view for that particular sensor type. This query ID is returned by the client.executeStatement() method used to create the materialized view. If we don’t have it saved, we can also find it by using the client to either list all running queries and filter for the relevant one, or describe the stream and table for the sensor type to find queries that read from and write to the stream and table. Here, we take the latter approach as it’s more efficient if there are many running queries.
public void removeSensorType(String sensorType) {
String tableName = sensorType + "_materialized";
SourceDescription streamDescription, tableDescription;
try {
streamDescription = client.describeSource(sensorType).get();
tableDescription = client.describeSource(tableName).get();
} catch (ExecutionException | InterruptedException e) {
throw new RuntimeException("Failed to describe stream/table", e);
}
Set<String> streamReadQueries = getQueryIds(streamDescription.readQueries());
Set<String> tableWriteQueries = getQueryIds(tableDescription.writeQueries());
// The query that populates the materialized view reads from the stream
// and writes to the table
Set<String> streamReadTableWriteQueries = new HashSet<>(streamReadQueries);
streamReadTableWriteQueries.retainAll(tableWriteQueries);
// There should be exactly one such query
if (streamReadTableWriteQueries.size() != 1) {
throw new RuntimeException("Unexpected number queries populating the materialized view");
}
// The ID of the query that populates the materialized view
String queryId = streamReadTableWriteQueries.stream().findFirst().orElse(null);
// ...
}
The getQueryIds() helper method simply transforms the list of queries returned by the client method into a set of strings:
private static Set<String> getQueryIds(List queries) {
return queries.stream()
.map(QueryInfo::getId)
.collect(Collectors.toSet());
}
Once we have the ID of the query to terminate, we can terminate the query and drop the source stream and sink table:
try {
client.executeStatement("TERMINATE " + queryId + ";").get();
client.executeStatement("DROP TABLE " + tableName + " DELETE TOPIC;").get();
client.executeStatement("DROP STREAM " + sensorType + ";").get();
} catch (ExecutionException | InterruptedException e) {
throw new RuntimeException("Failed to terminate the query and drop the stream and table", e);
}
The DELETE TOPIC flag in the DROP TABLE statement means that the underlying Kafka topic for the materialized view will be cleaned up as well, in contrast to the DROP STREAM statement that removes the stream from the ksqlDB server’s metadata but leaves the underlying Kafka topic intact.
Once again, we can rewrite the method using CompletableFuture composition to become non-blocking and clean up some of the error handling along the way:
public CompletableFuture<Void> removeSensorType(String sensorType) {
String tableName = sensorType + "_materialized";
return client.describeSource(sensorType)
.thenCombine(client.describeSource(tableName),
(streamDescription, tableDescription) -> {
Set<String> streamReadQueries = getQueryIds(streamDescription.readQueries());
Set<String> tableWriteQueries = getQueryIds(tableDescription.writeQueries());
// The query that populates the materialized view reads from the stream
// and writes to the table
Set<String> streamReadTableWriteQueries = new HashSet<>(streamReadQueries);
streamReadTableWriteQueries.retainAll(tableWriteQueries);
// There should be exactly one such query
if (streamReadTableWriteQueries.size() != 1) {
throw new RuntimeException("Unexpected number queries populating the materialized view");
}
// The ID of the query that populates the materialized view, as a String
return streamReadTableWriteQueries.stream().findFirst().orElse(null);
}).thenCompose(queryId -> client.executeStatement("TERMINATE " + queryId + ";"))
.thenCompose(result -> client.executeStatement("DROP TABLE " + tableName + " DELETE TOPIC;"))
.thenCompose(result -> client.executeStatement("DROP STREAM " + sensorType + ";"))
// Simplify return signature by returning null
.thenApply(result -> null);
}
Querying for latest sensor values
The Java client for ksqlDB may also be used to programmatically query the materialized views. Pull queries are best issued with the client.executeQuery() method as its return type blocks until all results are received from the server. This contrasts with the client.streamQuery() method, which establishes a streaming connection so that results may be consumed (via a Reactive Streams Subscriber) as they arrive and consequently is more suitable for push queries.
public List<Row> getLatestReadings(String sensorType, String sensorID) {
String tableName = sensorType + "_materialized";
String pullQuerySql = "SELECT * FROM " + tableName
+ " WHERE sensorID='" + sensorID + "';";
try {
return client.executeQuery(pullQuerySql).get();
} catch (ExecutionException | InterruptedException e) {
throw new RuntimeException("Failed to get latest readings", e);
}
}
Query results may be used to power a dashboard, drive automated alerts, or contribute to other parts of application logic.
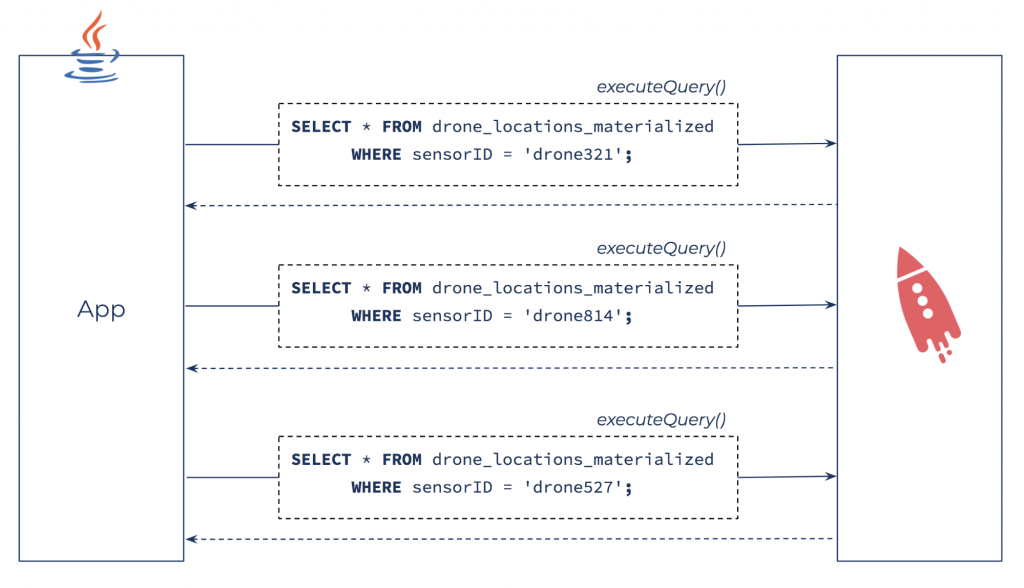 Query for the latest readings from particular sensors with the Java client for ksqlDB.
Query for the latest readings from particular sensors with the Java client for ksqlDB.
Conclusion
We’ve seen how the Java client for ksqlDB may be used to create and manage new streams, tables, and persistent queries; describe streams and tables for metadata, including their schemas; and issue pull queries against materialized views. The client also supports push queries (blocking and non-blocking); inserting new rows into existing ksqlDB streams; listing streams, tables, running queries, and Kafka topics; and more.
To check out the full code examples and play around with the demo yourself, visit GitHub.
You can also learn more and get started with the Java client for ksqlDB today with the usage and API docs, or contribute a new client in your favorite language! Feel free to drop by our #ksqldb Confluent Community Slack channel with any questions or feedback.
Get started with Confluent, for free
Watch demo: Kafka streaming in 10 minutes
Avez-vous aimé cet article de blog ? Partagez-le !
Abonnez-vous au blog Confluent



Introducing Versioned State Store in Kafka Streams
Versioned key-value state stores, introduced to Kafka Streams in 3.5, enhance stateful processing capabilities by allowing users to store multiple record versions per key, rather than only the single latest version per key as is the case for existing key-value stores today...


Delivery Guarantees and the Ethics of Teleportation
This blog post discusses the two generals problems, how it impacts message delivery guarantees, and how those guarantees would affect a futuristic technology such as teleportation.