[Webinar] Harnessing the Power of Data Streaming Platforms | Register Now
Enabling Exactly-Once in Kafka Streams
Get started with Confluent, for free
Watch demo: Kafka streaming in 10 minutes
This blog post is the third and last in a series about the exactly-once semantics for Apache Kafka®. See Exactly-once Semantics are Possible: Here’s How Kafka Does it for the first post in the series, which presents a high-level introduction to the message delivery and processing semantics of Kafka; and Transactions in Apache Kafka for the second post in the series, which covers the newly added transactions mechanism in Kafka, which is leveraged as the backbone to support the semantics. In this blog post we will continue the series by describing how the exactly-once semantics is achieved in the Kafka Streams API.
To read the other posts in this series, please see:
What is Kafka Streams?
The Kafka Streams API is a Java library included in Apache Kafka since the 0.10.0 release that allows users to build real-time stateful stream processing applications that process data from Kafka. Applications built with the Streams API can process real-time streaming data based on event time (i.e., when the data was actually generated in the real world) with support for late-arriving records, and can be elastically scalable, distributed, and fault-tolerant.
Exactly-Once as a Single Configuration Knob in Kafka Streams
In Apache Kafka’s 0.11.0 release, we leveraged the transaction feature in that same release as an important building block inside the Kafka Streams API to support exactly-once to users in a single knob. Stream processing applications written in the Kafka Streams library can turn on exactly-once semantics by simply making a single config change, to set the config named “processing.guarantee” to “exactly_once” (default value is “at_least_once”), with no code change required.
In the remainder of this blog we will describe how this is achieved by first discussing what exactly-once really means in the context of stream processing, why it’s so hard, and finally how Kafka Streams gets it done in the Kafka way.
What is Exactly-Once for Stream Processing?
Imagine you are about to build your first real-time stream processing application. One question you’d probably ask yourself is about “correctness:” given the input data, I expect my application always to generate the expected output. In the software engineering world, many common factors can affect correctness: a bug in your code, a bad config, a human error operating your system, etc. However, since your stream processing application does not take input as a static collection but a continuous stream of data, its correctness guarantee depends on one more critical condition: each record from the input data stream must be processed one time.
To be more specific, exactly-once for stream processing guarantees that for each received record, its processed results will be reflected once, even under failures. In the Apache Kafka world where data streams are represented as Kafka topics, we can rephrase these semantics a bit: as we have mentioned in the previous blog post, most stream processing applications today exhibit a read-process-write pattern where the processing logic can be formed as a function triggered for each record read from the continuous input Kafka topics, in which the processing state of the application is updated and zero or more records are generated to be produced to the output Kafka topics.
Exactly-once then means that the processing of any input record is considered completed if and only if state is updated accordingly and output records are successfully produced once.
If your stream processing application is executed in a single process, achieving exactly-once is relatively easy; however, if your application is running in parallel on multiple processes across a cluster of machines where failures become common, maintaining this guarantee is much harder.
To illustrate this we will describe a couple of common failure scenarios that could violate exactly once.
Exactly-Once: Why is it so Hard?
When building a read-process-write stream processing application with streaming data stored in Kafka, a common programming pattern would contain the following main loop:
- Fetch an input message A from one of the input Kafka topics (say topic TA).
- The processing function F is triggered for the fetched message A, and it updates its state from S to S’.
- Generate output messages B1, … Bn and send them to the output Kafka topics (let’s assume it is a single topic TB, while we can easily expand it to multiple topics).
- Wait for the sent output messages B1, … Bn to be acknowledged from the Kafka brokers.
- Commit the offset of the processed message A on TA, indicating that this message has been completed processing, and wait for the acknowledgment of the commit.
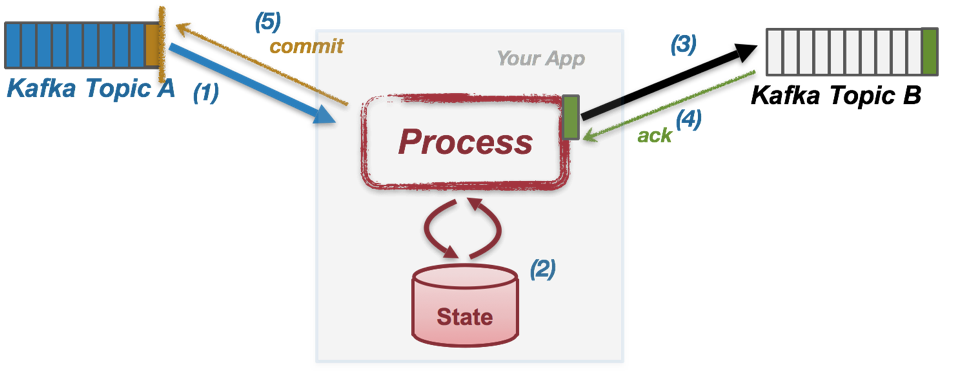
Note that in practice, steps 4) and 5) may not be executed within each loop iteration for each fetched message from the input Kafka topics, but will only be called after a number of messages have been fetched and processed to get better performance.
If no failure ever happens, then this implementation pattern could guarantee that each record’s processing results (i.e the state update and the output messages) are reflected exactly once. Now let’s look at what could happen when failures are brought into the picture.
Failure Scenario #1: Duplicate Writes
The first error scenario happens at step 4) above. Suppose a network partition happens between the Kafka broker hosting the leader replica of TB’s partition and the stream processing application. In this case, after the message has been successfully appended to TB’s partition log, broker’s acknowledgment response will not be successfully sent back and eventually, the application will get a timeout waiting for the response.
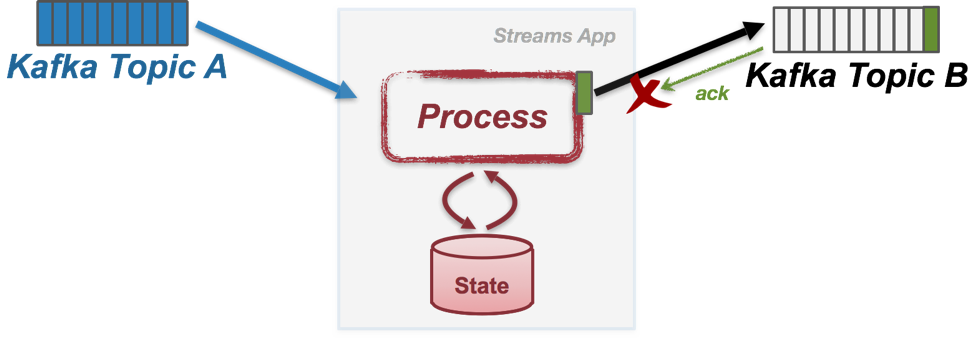
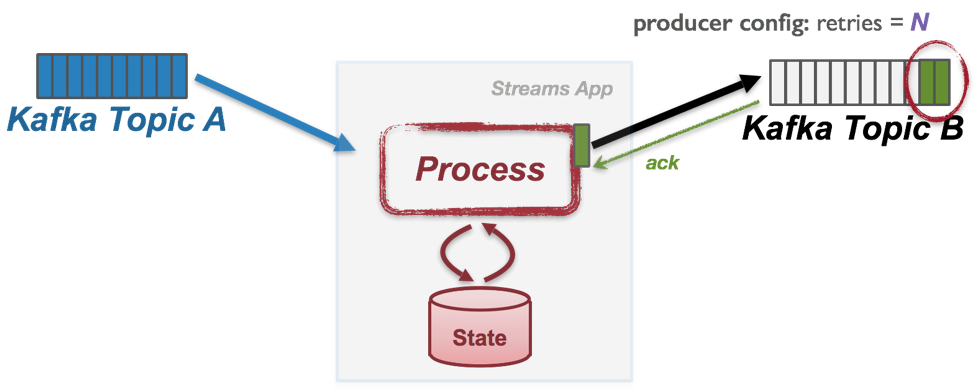
In this case, the application will usually retry sending the messages again since it does not know if the message has been successfully appended or not due to transient network partition (e.g. when using the Java producer client, you can set the producer’s “retries” config to do this). Eventually, the resend will succeed as network recovers, but the same output message would be appended multiple times in the output Kafka topic, causing “duplicated writes.”
Failure Scenario #2: Duplicate Processing
Now let’s consider another error scenario, which involves step 5) above. Suppose message A has been completely processed with the application state updated and persisted, and the output messages sent and acknowledged. However, before the application is about to commit the position of the processed message A it encounters a failure and crashes.
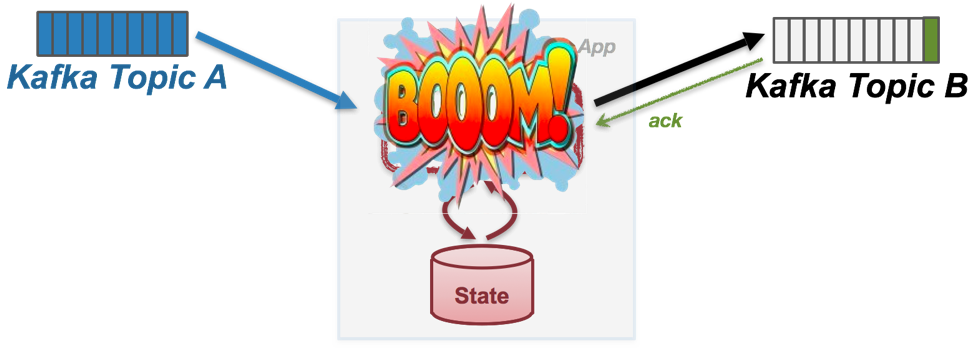
When restarting the application from the point of failure, we would then try to resume processing from the previously remembered position in the input Kafka topic, i.e. the committed offset. However, since the application was not able to commit the offset of the processed message A before crashing last time, upon restarting it would fetch A again. The processing logic will then be triggered a second time to update the state, and generate the output messages. As a result, the application state will be updated twice (e.g. from S’ to S’’) and the output messages will be sent and appended to topic TB twice as well. If, for example, your application is calculating a running count from the input data stream stored in topic TA, then this “duplicated processing” error would mean over-counting in your application, resulting in incorrect results.
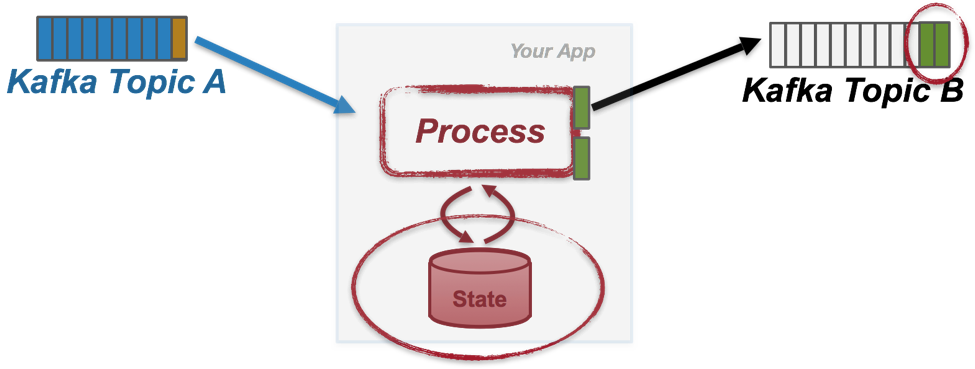
Today, many stream processing systems that claim to provide “exactly-once” semantics actually depend on users themselves to cooperate with the underlying source and destination streaming data storage layer like Kafka, because they simply treat this layer as a blackbox and hence does not try to handle these failure cases at all. Application user code then has to either coordinate with these data systems—for example, via a two-phase commit mechanism—to guarantee no data duplicates, or handle duplicated records that could be generated from the clients talking to these systems when the above mentioned failure happens.
So we have shown that under various failure scenarios, exactly-once semantics in your stream processing applications are quite hard to achieve. The next question then is, can we really make it easier with Kafka Streams?
How Kafka Streams Guarantees Exactly-Once Processing
Now we will describe what was implemented behind the scenes within Kafka Streams library to guarantee exactly-once when users turn on this config.
As we have mentioned in the previous section, a read-process-write stream processing application built around Kafka can be abstracted as a function F that is triggered for each message A read from the input Kafka topics. F is composed of three key steps:
- Update the application state from S to S’.
- Write result messages B1, … Bn to output Kafka topic(s) TB.
- Commit offset of the processed record A on the input Kafka topic TA.
Then in order to guarantee exactly-once, we need to make sure these three steps will be executed atomically: either all of them get executed, or none of them does.

While achieving atomicity for all these three steps is generally very hard for a stream processing technology, with Kafka in the picture we can actually map this hard problem into a simpler one.
First of all, in Apache Kafka we record offset commits by writing a message to an internal Kafka topic (called the offsets topic). So the third step above: committing offsets on the source topics, can be straightforwardly translated as just another message write to a specific Kafka topic.
Second of all, in Kafka Streams state updates can also be translated as a sequence of change capture messages. Here is why: in the Kafka Streams library, all state stores capture their updates by default into some special Kafka topics called the 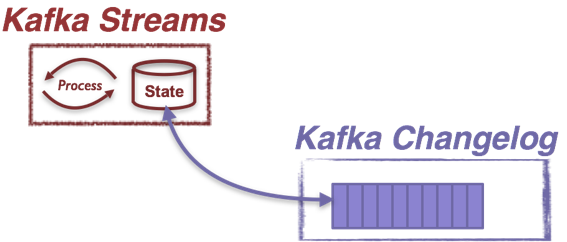 changelog topics. Each store keeps its updates in a separate changelog topic: whenever an update is applied to that store, a new record capturing this update will be sent to the corresponding changelog topic. A state store’s changelog topic is highly available through replication and is treated as the source-of-truth of the state store’s update history. This topic can hence be used to bootstrap a replica of the state store in another processor upon load balancing, fault recovery, etc. Therefore, any updates on a local state store from snapshot S to S’ can be captured by a sequence of state change messages stored in the Kafka changelog, as S1, … Sn.
changelog topics. Each store keeps its updates in a separate changelog topic: whenever an update is applied to that store, a new record capturing this update will be sent to the corresponding changelog topic. A state store’s changelog topic is highly available through replication and is treated as the source-of-truth of the state store’s update history. This topic can hence be used to bootstrap a replica of the state store in another processor upon load balancing, fault recovery, etc. Therefore, any updates on a local state store from snapshot S to S’ can be captured by a sequence of state change messages stored in the Kafka changelog, as S1, … Sn.
As a result, we can translate all the above three steps into a number of records sent to different topics:
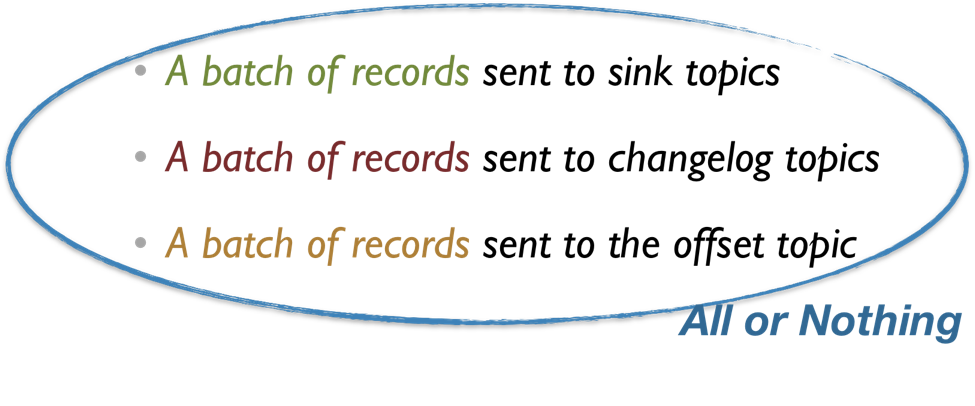 With the transactions API, we can enable producer clients to atomically send to multiple Kafka topic partitions. Messages written to multiple Kafka topics within the same transaction will be readable by consumers as a whole when the transaction is successfully committed, or none of them will not be readable at all if the transaction is aborted. By using this mechanism, Kafka Streams can ensure that records are sent to to the sink topics, the changelog topics, and the offset topics atomically.
With the transactions API, we can enable producer clients to atomically send to multiple Kafka topic partitions. Messages written to multiple Kafka topics within the same transaction will be readable by consumers as a whole when the transaction is successfully committed, or none of them will not be readable at all if the transaction is aborted. By using this mechanism, Kafka Streams can ensure that records are sent to to the sink topics, the changelog topics, and the offset topics atomically.
More specifically, when processing.guarantee is configured to exactly_once, Kafka Streams sets the internal embedded producer client with a transaction id to enable the idempotence and transactional messaging features, and also sets its consumer client with the read-committed mode to only fetch messages from committed transactions from the upstream producers.
Upon starting up the application, the embedded transaction producer will start the first transaction right away after the stream task has been initialized and is ready to begin processing. And whenever the application is going to commit the current processing state, it will use the embedded transactional producer to send the fetched position offsets from its consumer as part of its transaction, and then try to commit the current transaction and start a new one.
Now let’s see what will happen if failures occur: within a transaction, if a transient network partition happens and any of the sent records did not receive an acknowledgment in time, Streams with try sending the data again with the same transaction id. As we have learned from the previous blog, all messages sent by the same producer are idempotent (i.e. producer config enable.idempotence is set to true) such that when broker receives a duplicate message, it will ignore the record and return a DUP response to the client.
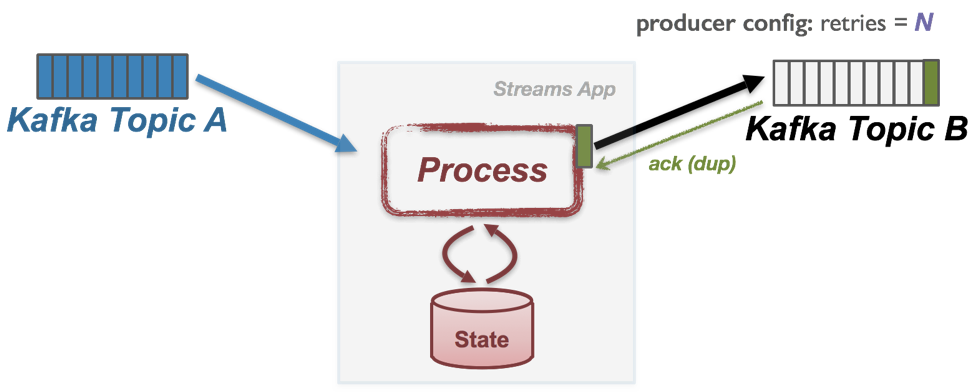
In addition, if any fatal error is encountered during normal processing or during the committing phase, Kafka Streams will let its producer abort the ongoing transaction before throwing the exception. By doing this, if the stream application task ever gets restarted with the same transaction id, we are assured that the last transaction from this id has been completed (either committed or aborted), and all the committed messages to the changelog topic, the offset topic and the output topics are from the same transaction (the golden bars shown in the Fig below).
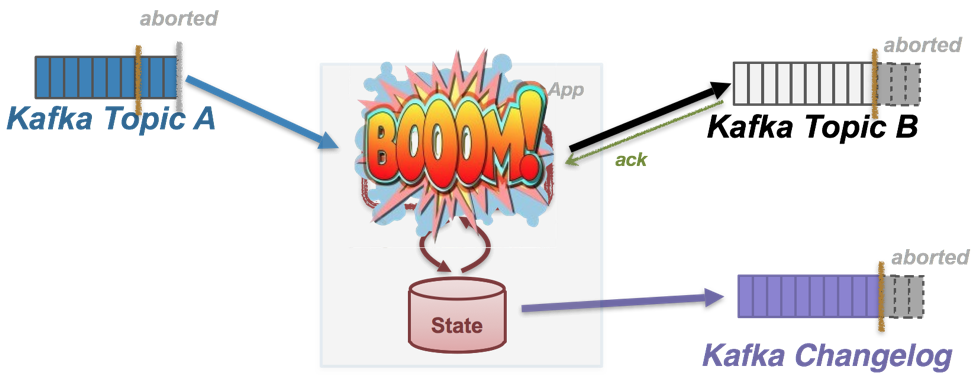
Remember that by replaying this sequence of changelog messages, we can always restore the local state store up to S’. Therefore after the processor state has been restored and the task is ready to resume processing, its state will be in a consistent snapshot with the committed offsets and the output messages, hence guaranteeing exactly once semantics.
Streams Performance Implications
As we have mentioned in the previous blog post, the write amplification cost of a transaction is constant and independent of the number of messages written within the partition. Thus, the larger the transaction in terms of messages, the smaller the amortized cost. However, larger transactions will also result in longer end-to-end processing latency because the consumer in read-committed mode can fetch the messages of a transaction only when the transaction has been committed.
In Kafka Streams, because a new transaction is created whenever commit is called, the average transaction size is determined by the commit interval: with the same incoming traffic, a shorter commit interval will result in smaller transactions. In practice users should therefore tune the commit.interval.ms setting when exactly-once is enabled to make a good trade-off between throughput versus end-to-end processing latency.
Further reading
We have just provided a high-level overview on how Kafka Streams achieves exactly-once with transactions. Needless to say there are still a lot of details in the design and implementation that are not covered here. If you are interested in learning more about these details, please refer to the following relevant documents online:
- Idempotent and transactional messaging KIP: This provides good background on the data flow and an overview of the public interfaces of transactions, particularly the configuration options that come along with transactions.
- Kafka Streams exactly-once KIP: This provides an exhaustive summary of proposed changes in Kafka Streams internal implementations that leverage transactions to achieve exactly-once.
- The original design document on exactly-once support in Kafka Streams: This is the detailed design of the above KIP proposal, covering how to commit task states while handling corner cases and errors, how to differentiate clean and unclean shutdowns, how to fence zombie processors, etc.
- The Kafka Summit talk that provides more context and motivations on the exactly-once semantics and its use cases in the real-world applications.
- Exactly-Once Semantics Are Possible: Here’s How Kafka Does It: Part 1 of this blog series.
- Transactions in Apache Kafka: Part 2 of this blog series.
Conclusion
In this post, we learned about why exactly-once is important for stream processing applications, and how this guarantee is supported in the Streams API of Apache Kafka by leveraging the transaction feature introduced in 0.11 release. Using this powerful functionality is very easy from an application developer’s perspective: all you need to leverage exactly-once processing semantics in your own applications is to set a single configuration knob—no code change is required.
About Apache Kafka’s Streams API
If you have enjoyed this article, you might want to continue with the following resources to learn more about Apache Kafka’s Streams API:
- Get started with the Kafka Streams API to build your own real-time applications and microservices.
- Walk through our Confluent tutorial for the Kafka Streams API with Docker and play with our Confluent demo applications.
Get started with Confluent, for free
Watch demo: Kafka streaming in 10 minutes
Avez-vous aimé cet article de blog ? Partagez-le !
Abonnez-vous au blog Confluent



Introducing Versioned State Store in Kafka Streams
Versioned key-value state stores, introduced to Kafka Streams in 3.5, enhance stateful processing capabilities by allowing users to store multiple record versions per key, rather than only the single latest version per key as is the case for existing key-value stores today...


Delivery Guarantees and the Ethics of Teleportation
This blog post discusses the two generals problems, how it impacts message delivery guarantees, and how those guarantees would affect a futuristic technology such as teleportation.