Introducing Connector Private Networking: Join The Upcoming Webinar!
Confluent Platform 2.0 is GA!
Get started with Confluent, for free
Watch demo: Kafka streaming in 10 minutes
We are very excited to announce the general availability of Confluent Platform 2.0. For organizations that want to build a streaming data pipeline around Apache Kafka, Confluent Platform is the easiest way to get started. It includes a set of components out-of-the-box that we saw being built over-and-over again in-house by some of the largest companies in the world, as they transitioned to a central stream data platform. We’ve learned from these companies and packaged together an open source implementation of these components in a single, well tested, fully supported product. It’s 100% open source and you can download it now.
Confluent Platform 2.0
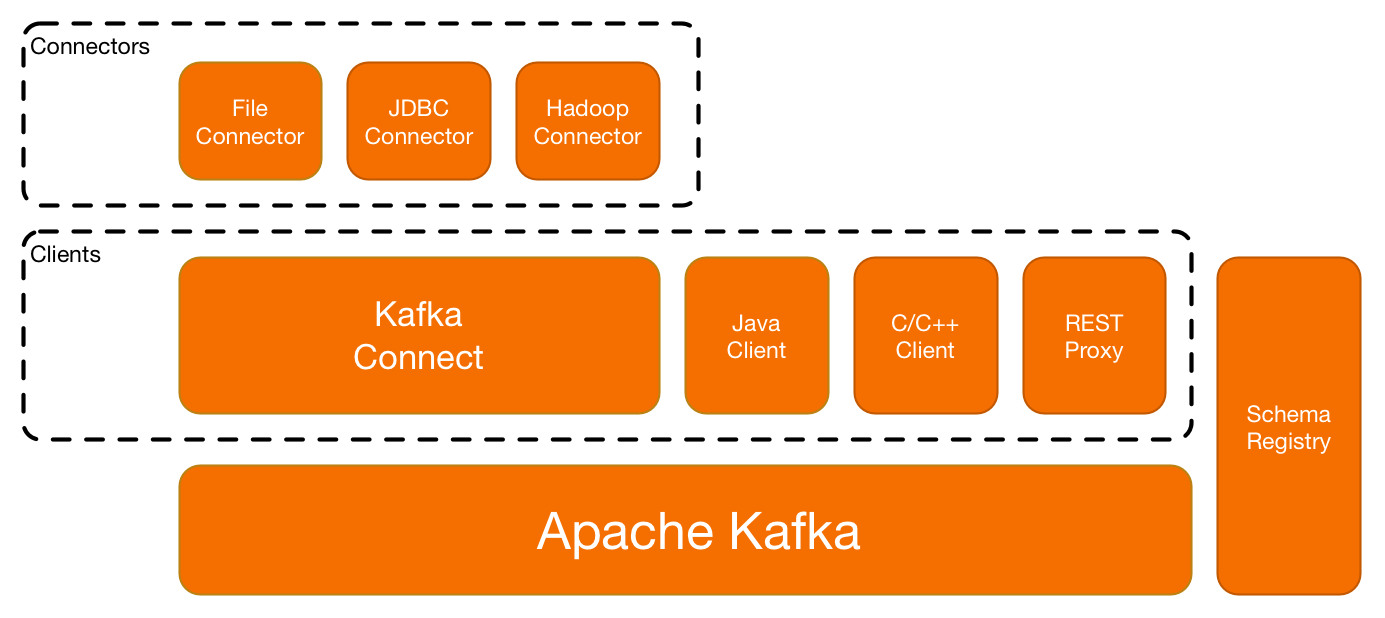
In Confluent Platform 2.0 we’ve added new features to enable the operation of Apache Kafka as a centralized stream data platform. This entails adding the ability to operate multi-tenant Kafka clusters and enabling data flow from existing systems to Kafka. To enable multi-tenancy, this release adds security and user-defined quotas. To enable streaming data flow between existing data systems, this release adds Kafka Connect and better client support.
Confluent Platform 2.0 includes Apache Kafka 0.9* and offers:
Security
This release adds three key security features to Kafka. First, administrators can require client authentication (using either Kerberos or TLS client certificates), so that Kafka knows who is making each request. Second, unix-like permissions system can be used to control which users can access which data. Third, Kafka supports encryption of network connections, allowing messages to be securely sent across untrusted networks.
These are only the first of many security features to be added to the Confluent Platform, and we look forward to adding more security capabilities in forthcoming releases.
Kafka Connectors
Kafka Connect
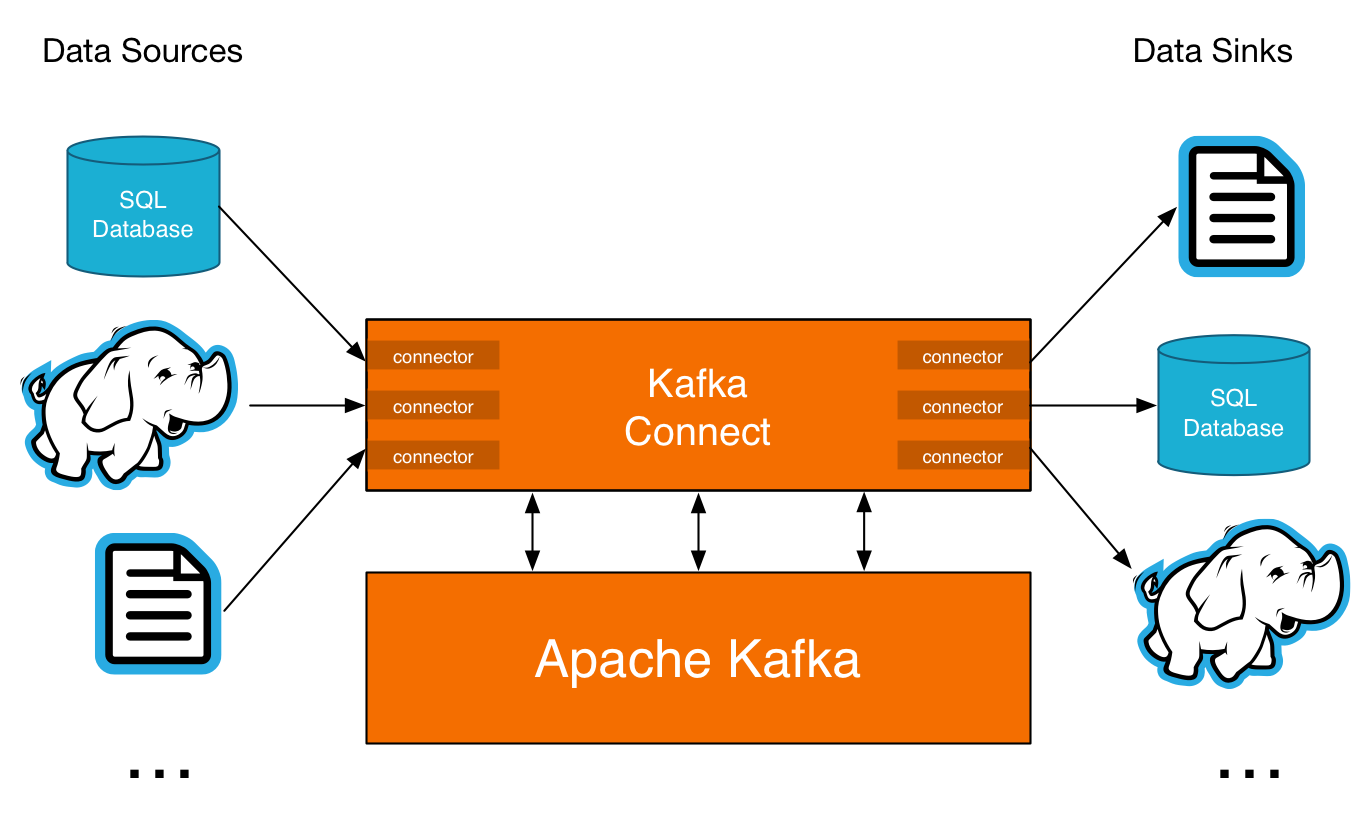
Kafka enables real-time, high scale flow of stream data between various systems, unlocking data silos along the way. This capability is really solid, and drives Kafka’s popularity, but we sought to make Kafka even more powerful in this regard – adding a new feature called Kafka Connect.
Kafka Connect facilitates large-scale, real-time data import and export for Kafka while offering fault tolerance, partitioning, offset management, strong delivery semantics, operations, and monitoring. Kafka Connect is a tool for copying data between Kafka and a variety of other systems, ranging from relational databases, to logs and metrics, to Hadoop and data warehouses, to NoSQL data stores, to search indexes, and more.
The 2.0 release of Confluent Platform includes open source, tested and certified Kafka connectors for log files, relational databases, and Hadoop. These connectors are fully integrated with the Confluent Schema Registry to enable, for instance, end-to-end ETL for databases into Hadoop. The HDFS Connector allows you to export data from Kafka topics to HDFS files in a variety of formats and integrates with Hive to make data immediately available for querying with HiveQL. The JDBC Connector allows you to import data from any relational database with a JDBC driver into Kafka topics. By using JDBC, this connector can support a wide variety of databases without requiring custom code for each one. We’re still shipping Camus in this release before phasing it out in forthcoming releases.
We look forward to working closely with the open source community to foster development of a rich ecosystem of Kafka connectors. If you’d like to contribute connectors, start by going through the connector developer guide or reach out to the Confluent Platform mailing list.
User-defined Client Quotas
This release of Confluent Platform offers user-defined quotas in Kafka, an important capability for managing multi-tenant Kafka clusters. These quotas give the user the ability to prevent a rogue client from monopolizing the broker resources and thereby making the cluster unavailable to the rest of the clients. With this feature, users can allocate a quota on the bandwidth usage to clients that is proportional to their expected traffic. This allows the Kafka cluster to throttle the traffic from clients, should they violate their allocated quota, thereby protecting the other tenants on the same cluster.
More and better clients
Confluent Platform 2.0 includes fully-featured native Java producer and consumer clients. It also includes fully supported, high performance C/C++ clients. These clients have feature and API parity with the Apache Kafka 0.9 Java clients and are also integrated with Confluent Platform’s Schema Registry.
Open Source
Confluent Platform is entirely open source. We are proud to share our work with the broader Kafka Community and invite community members to help improve Kafka. Developers and users can get access to the source code here.
How Do I Get Confluent platform 2.0?
We’re really excited about the latest Confluent Platform release! Learn more about it by reading the details in the Confluent Platform 2.0 documentation. Download it to give it a spin.
Confluent Platform 2.0 is also backed by our subscription support, and we also offer expert training and technical consulting to help get your organization started.
As always, we are happy to hear your feedback. Please post your questions and suggestions to the public mailing list.
*Confluent Platform 2.0 bundles a version of Apache Kafka 0.9 that includes additional patches that increase performance, stability, and security, all of which have been contributed to Apache Kafka.
Get started with Confluent, for free
Watch demo: Kafka streaming in 10 minutes
Avez-vous aimé cet article de blog ? Partagez-le !
Abonnez-vous au blog Confluent



Schema Registry Clients in Action
Learn about the bits and bytes of what happens behind the scenes in the Apache Kafka producer and consumer clients when communicating with the Schema Registry and serializing and deserializing messages.

How to Securely Connect Confluent Cloud with Services on Amazon Web Services (AWS), Azure, and Google Cloud Platform (GCP)
The rise of fully managed cloud services fundamentally changed the technology landscape and introduced benefits like increased flexibility, accelerated deployment, and reduced downtime. Confluent offers a portfolio of fully managed...