Introducing Connector Private Networking: Join The Upcoming Webinar!
CloudBank’s Journey from Mainframe to Streaming with Confluent Cloud
Get started with Confluent, for free
Watch demo: Kafka streaming in 10 minutes
Cloud is one of the key drivers for innovation. Innovative companies experiment with data to come up with something useful. It usually starts with the opening of a firehose that continuously broadcasts tons of events before they start mining it to create music out of simply noise.
Today, companies from all around the world are witnessing an explosion of event generation coming from everywhere, including their own internal systems. These systems emit logs containing valuable information that needs to be part of any company strategy. But to perform all this experimentation; companies cannot wait weeks or even months for IT to get them the appropriate infrastructure so they can start innovating, hence why cloud computing is becoming a standard for new developments.
But cloud alone doesn’t solve all the problems. A trend often seen in organizations around the world is the adoption of Apache Kafka® as the backbone for data storage and delivery. This trend has the amazing effect of decreasing the number of SQL databases necessary to run a business, as well as creates an infrastructure capable of dealing with problems that SQL databases cannot. Different data problems have arisen in the last two decades, and we ought to address them with the appropriate technology.
We need something that can handle large amounts of data, something that can handle unstructured data coming from logs and social media, and data in their native form. We need something that does not only store data but processes events as they happen. And on top of all that, we need something that can deliver this data for as many applications as necessary, in real time, concurrently and reliably. In other words, along with the cloud, there is a need to manage data differently.
CloudBank is a hypothetical example of a company that embraced all of this at its heart. This case study is based off real, concrete war stories, and will detail how Confluent Cloud™ was a key enabler for their digital strategy, unfolding new ways to capitalize on their product and differentiate their business, by leveraging the power of Apache Kafka and the cloud at the same time.
Journey from mainframe to cloud
CloudBank started their business writing custom software for private banks running mainframes. They operated as software consultants hired to work side by side with banks, helping them with project implementation and ensuring code best practices. Throughout almost two decades, CloudBank accumulated a great deal of experience about the banking business, as well as built many important relationships with banks.
Eventually, they decided to create their own flagship product called Genesis, a core banking software package that delivers functionality such as payments, withdrawals, loan, and credit processing, so banks can offer these functions via their ATMs and online and mobile channels. Like any core banking software, the idea is to help banks offload their IT, letting the banks worry only about the infrastructure necessary to run it. With banks able to spend less time maintaining systems and more time innovating their business, CloudBank has begun to differentiate itself from competitors.
Core banking is where everything starts in the banking business.
–CEO of CloudBank, explaining the origins of the product’s name
The Genesis product wasn’t a hit at first, but it became popular after the explosion of FinTech in recent years. Multiple startups became aware of the popularity of Genesis and decided to partner up with CloudBank to come up with the next generation of software for banks.
While discussing what would be the best course of action to get Genesis up to speed, several startups unanimously recommended offering Genesis as a SaaS product, enabling CloudBank to create a new line of business to address the digital era. Thus far, Genesis had been created to be this on-prem software that banks would install in their own infrastructure, while CloudBank would take care of supporting their operations through specialized consulting. That certainly was attractive to many banks since removing core banking software from their responsibility already minimizes a lot of the IT cost. Nevertheless, Genesis was still a thing that banks would look as cost and not as value.
We started our careers writing COBOL programs for mainframes, so the idea of running software in the cloud wasn’t so clear to us before talking with the startups. They made us realize the potential that cloud can offer to our business.
–CEO of CloudBank after meeting with the startups
After several meetings with startups, CloudBank decided to take their second most important step in the history of their business: Move Genesis to the cloud. With careful consideration, one of the startups was selected to build the first release of Genesis in the cloud, due to their experience in creating cloud-native applications using Java—the same programming language used to create Genesis.
A very important requirement for the first release of Genesis in the cloud was to provide for their customers the ability to choose which cloud vendor they would like to use. This was also recommended by one of the banks that had been a customer of CloudBank since the first release of Genesis. Banks know better than anyone else the price of being locked into a specific provider and how bad this is when they want to innovate using different tools and technologies.
We want our customers to fully experience the cloud by taking advantage not only of the security and scalability features of it but also the ability to decrease TCO based on which cloud provider they choose to use.
–CTO of CloudBank
Building Genesis to offer multi-cloud support wasn’t easy though, but since they decided on this approach since day one, that eased things a bit. The startup selected to build Genesis on the cloud had explained how hard refactoring an application to run in another cloud provider is when the code is written to run in a specific one. They had this experience in the past with one major cloud provider that at first made things easier for them to develop their application by offering off-the-shelf SDKs. But eventually, they realized how dependent on the proprietary SDKs they were, and how that was negatively affecting their ability to innovate.
We had this problem while developing Genesis for on-prem. We decided to write our code for one specific Java EE application server, and that cost us the ability to run the software in other Java EE application servers required by other banks.
–CTO of CloudBank
Genesis then relied on multiple abstraction layers that made the software portable across cloud providers. The first layer would abstract infrastructure details such as compute, network, firewalls, and storage—and they used Terraform to implement that. Thus, they created different Terraform scripts for each cloud provider that would be offered as an option, such as Amazon Web Services (AWS), Google Cloud and Microsoft Azure. The second layer would abstract platform details such as clustering, deployment, scaling up and out, etc. This layer was implemented using a combination of Docker and Kubernetes, and certainly was one of the best design decisions that the team ever made. It allowed developers to focus on writing code that adapts the existing business logic from the existing core banking software.
The second layer would abstract platform details such as clustering, deployment, scaling up and out, etc. This layer was implemented using a combination of Docker and Kubernetes, and certainly was one of the best design decisions that the team ever made. It allowed developers to focus on writing code that adapts the existing business logic from the existing core banking software.
There is only one truth: The log
One of the key characteristics of core banking software is serving customers over multiple channels in a secured manner. ATMs and internet/mobile banking constitute the majority of channels used by banks. Through these channels, customers can perform many of the functions provided by core banking, and naturally, this only makes sense if customers are looking to the same data regardless of the channel.
Keeping data in sync is also important for any core banking software. Whether customers are using their mobile phone to check their savings or getting a hard copy report directly from a branch, the data needs to be the same. When Genesis was merely an on-prem application, that usually was not a problem because each bank could keep the data in a central location—usually a corporate database instance—where the software installed on each branch would simply point to that location.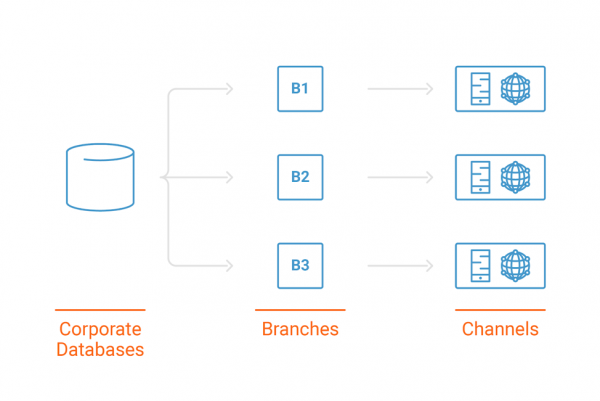 This architecture is functional but has lots of drawbacks. Firstly, it relies on data replication to keep the branches and the channels in sync. Since replication cannot occur every second without slowing down the databases, it is often configured to occur outside peak business hours. This forces the software to rely on day-old data, which is not enough for the we-want-it-and-we-want-it-now type of customers.
This architecture is functional but has lots of drawbacks. Firstly, it relies on data replication to keep the branches and the channels in sync. Since replication cannot occur every second without slowing down the databases, it is often configured to occur outside peak business hours. This forces the software to rely on day-old data, which is not enough for the we-want-it-and-we-want-it-now type of customers.
Secondly, this architecture is very costly. It requires that multiple databases be installed over different locations and branches. Not only are there license costs (TCA) but also there are maintenance costs (TCO). Thirdly, relying on databases to keep data is not the wiser option today if you want to handle all types of data.
As mentioned earlier, companies today need to be able to process not only transactional data but also unstructured data coming from sources like logs. CloudBank had evaluated NoSQL databases for this case but ruled them out because both SQL and NoSQL databases were designed to process data after they had been persisted, which typically entails a batch-oriented style of processing that doesn’t easily deliver the near real-time semantics required by Genesis.
We want a single source of truth for our data. It needs to handle all types of data and make it available not just for one but multiple applications simultaneously.
–CTO of CloudBank
This is when CloudBank selected Apache Kafka as technology enabler for their needs. Not only does Apache Kafka provide the level of reliability, durability, and security delivered by databases, but it also provides unbeatable performance while keeping costs low, due to its ability to be executed in cheap commodity hardware. Kafka organizes data into a distributed commit log where data is continuously appended to the tail, allowing high density (i.e., more data per server) and constant retrieval time.
Kafka quickly became the heart of their core banking software, allowing the development of new functionalities to be much easier, with Kafka handling the entire communication asynchronously and being the source of truth they needed. The first release of Genesis was based on Apache Kafka 2.0 from the community, where the engineering team had to provision and deploy the software all by themselves.
At first, that was not a problem since the scenarios that made up their MVP (Minimum Viable Product) didn’t require any data consistency to be in place—they were essentially report based. However, by the time they started testing transactions executing concurrently over multiple channels, they saw that having Apache Kafka running in the Cloud was a significant challenge.
Apache Kafka itself was not the problem, as the engineering team was quite familiar with the Producer, Consumer and Kafka Streams APIs. It was keeping the brokers running smoothly, and serving the core banking software efficiently and cost-effectively was getting hard. The cloud introduces a whole new set of challenges related to handling failures across multiple availability zones, replication over regions, implementation of minimum recovery point objective (RPO) and recovery time objective (RTO) for disaster recovery strategies, etc.
And while microservices and stateless applications are great candidates for leveraging the power of Kubernetes, which would ultimately solve this problem, stateful software such as Apache Kafka requires a whole new level of expertise, one that CloudBank didn’t have as their business is core banking. Kubernetes is great but should not be used as a silver bullet for any workload.
After the first release of Genesis, the engineering team started to wonder what could be done to completely abstract Apache Kafka from their deployment but still maintain it as the heart of core banking software. They knew that this would be paramount if they would like to keep Genesis simple and affordable for both CloudBank and their customers.
Perfect balance with Confluent Cloud
It was around 11:00 p.m. when the CTO of CloudBank got a call from the architect responsible for the cloud version of Genesis.
We won’t be able to deliver the second release in time. We are spending too much time with Apache Kafka and almost zero time writing code for the functionalities.
–Architect of Genesis
The next morning, there was a meeting with the engineering team, and the CTO asked why the Apache Kafka deployment was taking so much of their time. After a detailed explanation of what had been the focus of the team during the past few weeks, they realized that most of their time was spent with details that they hadn’t thought through during the design phases. Some of these details were considered simple initially but eventually became hard problems—while others had unfolded during the development of the software. In other words, they underestimated the complexity of running Apache Kafka in the cloud.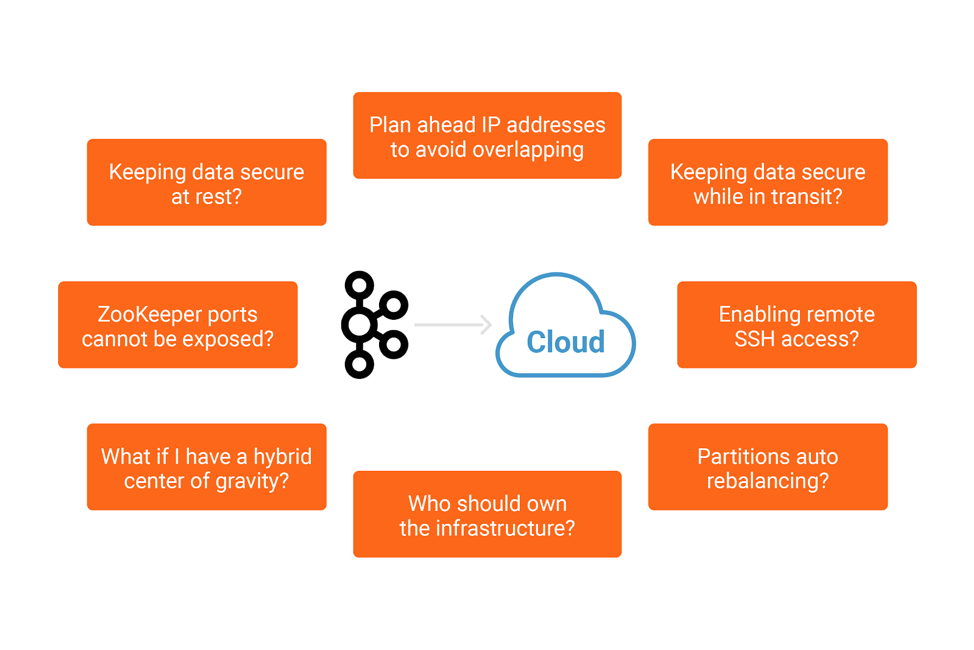 Both the CTO and the engineering team started looking for cloud-based products that would deliver Apache Kafka as a service, but there were only a few. Of the solutions available, none shared the same design principles that Genesis required, such as multi-cloud support, a mature set of capabilities for stream processing, the ability to be highly available over multiple availability zones and, most importantly, the ability to be managed for someone that really understands how Apache Kafka works.
Both the CTO and the engineering team started looking for cloud-based products that would deliver Apache Kafka as a service, but there were only a few. Of the solutions available, none shared the same design principles that Genesis required, such as multi-cloud support, a mature set of capabilities for stream processing, the ability to be highly available over multiple availability zones and, most importantly, the ability to be managed for someone that really understands how Apache Kafka works.
That last item was the most common concern raised by the engineering team; which had terrible experiences in the past dealing with cloud providers that would simply ship open source code in their environments, but could not handle a support ticket containing more advanced questions that couldn’t be easily Googled.
As their next step, they got in touch with Confluent, the company founded by the creators of Apache Kafka, to ask for guidance. They explained their concern about having a way to use Apache Kafka but without the need to manage clusters by themselves. They also explained that they were looking for a service that could be as reliable as their business needs to be, with clusters being managed by someone that really understands how the Apache Kafka technology works.
Apache Kafka was a great starting point, but Confluent allowed us to complete the journey.
–CTO of CloudBank
After careful consideration of CloudBank requirements, Confluent recommended the usage of Confluent Cloud, an easy-to-use service that rapidly became the missing piece for Genesis architecture. Confluent Cloud integrates with the Confluent Platform for a persistent bridge between private data centers and public clouds for hybrid environments. It is available on multiple cloud providers, which ensures no vendor lock-in, and it is managed by the people that write Apache Kafka, therefore delivering the level of SLA and support that CloudBank requires for its business continuity.
Confluent Cloud was the perfect balance for Genesis. The engineering team could focus on coding while Confluent took care of the Kafka clusters. Because Confluent Cloud supports the notion of VPC peering in a given cloud provider, VPCs can be peered so that the applications producing and consuming records to/from Kafka can communicate with the clusters directly instead of relying on the public internet. This practice ensures better security while minimizing the network bandwidth necessary to send and receive records. That allowed Genesis to create a symbiosis with Confluent Cloud clusters, as they heavily use VPCs to isolate the applications in their deployment.
Finally, Confluent Cloud allowed CloudBank to think of better ways to offer value to its customers through the Genesis software. Since Confluent Cloud allows access to the exciting set of tools from Confluent Platform, the engineering team can use these tools to elegantly process a stream of events with ksqlDB, build ETL pipelines, feed data in and out of topics using Kafka Connect and its vibrant ecosystem of connectors (i.e., MQTT, REST, JMS, S3, Elasticsearch) and monitor their clusters using Confluent Control Center.
Thanks to Confluent, we can now focus on innovating our business. Everything else related to Kafka has been taken care of.
–CEO of CloudBank
I hope you enjoyed reading this hypothetical case study inspired by real war stories. To learn more about Apache Kafka as a service: Check out Confluent Cloud, a fully managed event streaming data service based on Apache Kafka. Use the promo code CL60BLOG to get an additional $60 of free Confluent Cloud usage.*
Get started with Confluent, for free
Watch demo: Kafka streaming in 10 minutes
Avez-vous aimé cet article de blog ? Partagez-le !
Abonnez-vous au blog Confluent



Confluent’s Customer Zero: Building a Real-Time Alerting System With Confluent Cloud and Slack
Turning events into outcomes at scale is not easy! It starts with knowing what events are actually meaningful to your business or customer’s journey and capturing them. At Confluent, we have a good sense of what these critical events or moments are.


How To Automatically Detect PII for Real-Time Cyber Defense
Our new PII Detection solution enables you to securely utilize your unstructured text by enabling entity-level control. Combined with our suite of data governance tools, you can execute a powerful real-time cyber defense strategy.