Fast, Frictionless, and Secure: Explore our 120+ Connectors Portfolio | Join Webinar!
The Changing Face of ETL
Get started with Confluent, for free
Watch demo: Kafka streaming in 10 minutes
The way in which we handle data and build applications is changing. Technology and development practices have evolved to a point where building systems in isolated silos is somewhat impractical, if not anachronistic. As the cliché of a cliché goes, data is the new oil, the lifeblood of an organization—however you want to analogize it, the successful handling and exploitation of data in a company is critical to its success.
In this article, we’re going to see a practical example of a powerful design pattern based around event-driven architectures and an event streaming platform. We’ll discuss why companies are identifying real-time requirements and adopting this instead of legacy approaches to integrating systems.
Part of this shift comes from the blurring of lines between analytic systems and transactional systems. In the old days, we built transactional systems on which our business ran, and then a separate team would be responsible for extracting the data and building analytics (or BI, or MIS or DSS, depending on your age) on that. It was done in an isolated manner and was typically a one-way feed. Analytics teams took the data, on which processing was done, to cleanse and enrich it before building reports.
Now, we have the beginnings of an acceptance that data is not only generated by systems but when combined with other data and insights can actually be used to power systems. It’s about enabling the integration of data across departments, teams and even companies, making it available to any application that wants to do so and building this in such a way that is flexible, scalable and maintainable in the long term. And with today’s technology, we can do so in real time, at scale.
For example, retail banks are faced with the challenge of providing a compelling customer experience to a new generation of users, whose expectations are shaped by AI-powered mobile applications from Google and Apple. In order to meet this challenge, they need to combine everything they know about their customers with state-of-the-art predictive models, and provide the results to mobile apps, web apps and physical branches. ING Bank and Royal Bank of Canada use event-driven architectures to power modern systems that do exactly that. Let’s dive into the technologies and design patterns that enable them to transform their user experience and development process at the same time.
ETL but not as you know it
First, a bit of history about ETL. It got its start back in the 1970s as more businesses were using databases for business information storage. The more data they collected, the greater the need for data integration. ETL was the method chosen to help them take the data from all these sources, transforming it, and then loading it to the desired destination. Hence the name ETL (extract, transform, load).
Once data warehouses became more common in the 80s and 90s, users could access data from a variety of different systems like minicomputers, spreadsheets, mainframes and others. Even today, the ETL process is still used by many organizations as part of their data integration efforts. But as you will see, ETL is undergoing a fascinating change.
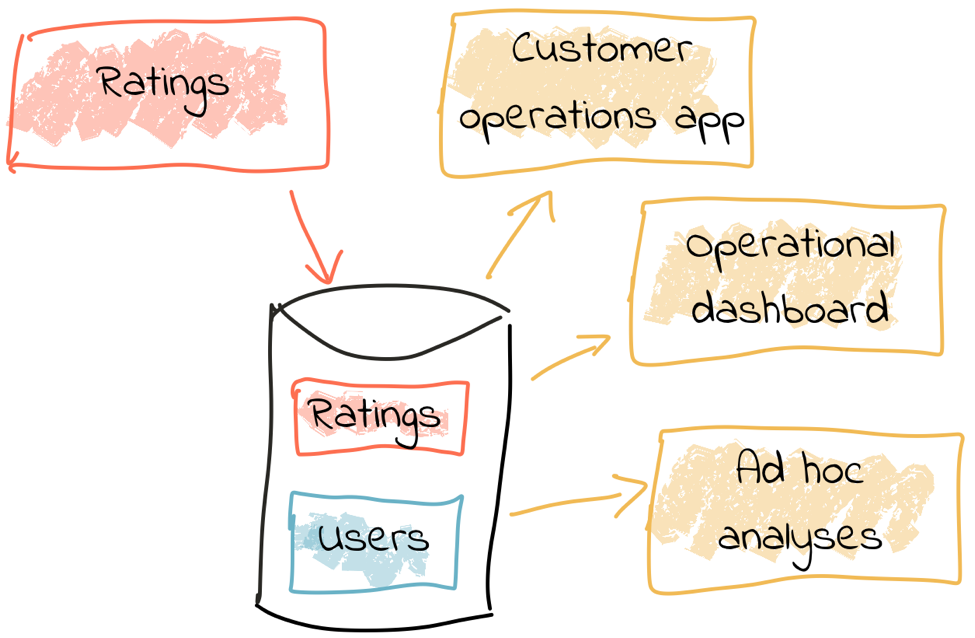
Consider a simple example from the world of e-commerce: On a website, user reviews are tracked through a series of events. Information about these users such as their name, contact details and loyalty club status is held on a database elsewhere. There are at least three uses for this review data:
- Customer operations: If a user with high loyalty club status leaves a poor review, we want to do something about it straight away to reduce the risk of them churning. We want an application that will notify us as soon as a review meeting this condition is met. By doing so immediately, we can offer customer service that is far superior than if we had waited for a batch process to run and flag the user for contact at a later date.
- Operational dashboards showing a live feed of reviews, rolling aggregates for counts, median score and so on—broken down by user region, etc.
- Ad hoc analytics on review data combined with other data (whether in a data lake, data warehouse, etc.): This could extend to broader data science practices and machine learning use.
All of these use cases require access to the review information along with details of the user.
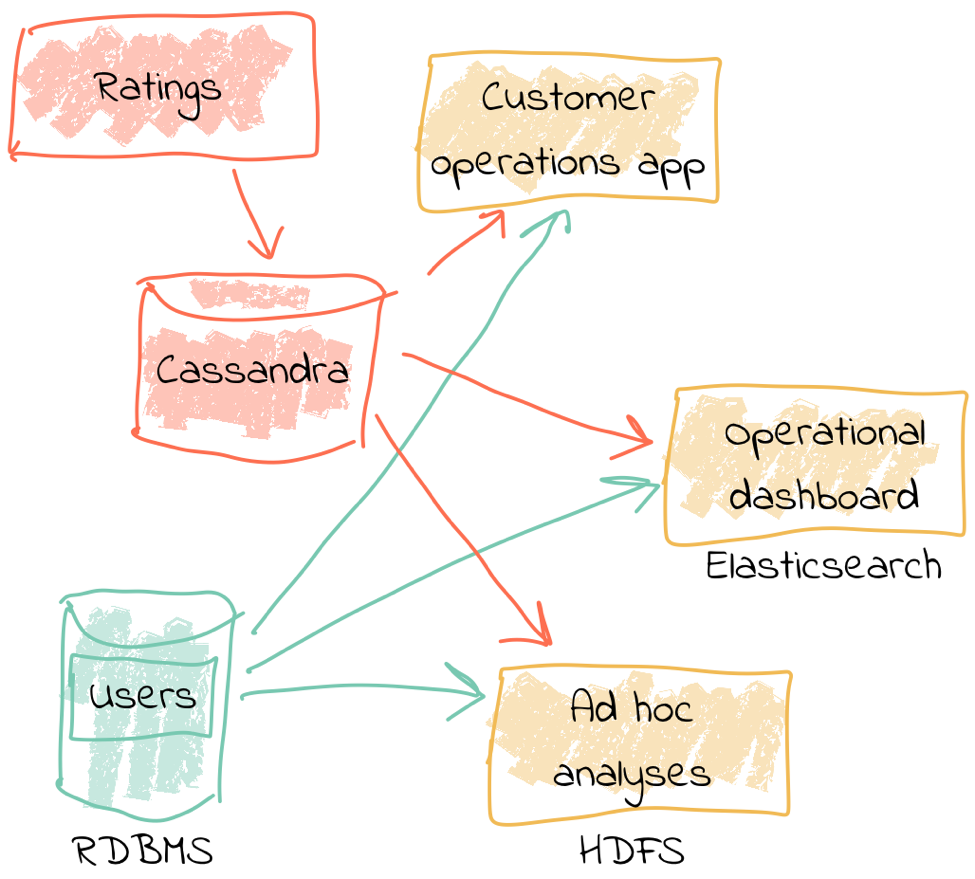
One option is to store the reviews in a database, against which we then join a user table. Perhaps we drive all the requirements against the data held in this database. There are several challenges to this approach, however. Because we are coupling together three separate applications to the same schema and access patterns, it becomes more difficult to make changes to one without impacting the others. In addition, one application may start to impact the performance of another—consider a large-scale analytics workload and how this could affect the operational behavior of the customer ops alerting application.
In general, we would not expect to build the three applications against the same data store. Thus, we extract the review and user data to target systems best suited for serving the dependent application. Perhaps we use a NoSQL store to drive the customer operations application, the Elastic Stack for the ops dashboard and something like HDFS, Amazon S3, Google BigQuery or Snowflake for the analytics platform.
But now, the following questions emerge:
- How do we populate each target from the review data in a consistent and efficient way?
- How do we enrich the review data with user information? Do we try and do it once before loading each target, or do we repeat the process as part of loading each target? Can we do this with up-to-date versions of the customer data while also maintaining a low-latency feed?
We also have longer-term architectural considerations. If we add new sources for the review data (e.g., mobile application, public API), how is that fed to the target systems? What if one of the target systems is offline or running slowly? How do we buffer the data or apply backpressure? If we want to add new targets for the data in the future, how easy will it be to do this?
You say tomato; I say tomato
In the past we used ETL techniques purely within the data-warehousing and analytic space. But, if one considers why and what ETL is doing, it is actually a lot more applicable as a broader concept.
- Extract: Data is available from a source system
- Transform: We want to filter, cleanse or otherwise enrich this source data
- Load: Make the data available to another application
There are two key concepts here:
- Data is created by an application, and we want it to be available to other applications
- We often want to process the data (for example, cleanse and apply business logic to it) before it is used
Thinking about many applications being built nowadays, particularly in the microservices and event-driven space, we recognize that what they do is take data from one or more systems, manipulate it and then pass it on to another application or system. For example, a fraud detection service will take data from merchant transactions, apply a fraud detection model and write the results to a store such as Elasticsearch for review by an expert. Can you spot the similarity to the above outline? Is this a microservice or ETL process?
ETL is a design pattern, applicable to a huge variety of purposes beyond traditional data warehousing from which it originated.
The event streaming platform in action
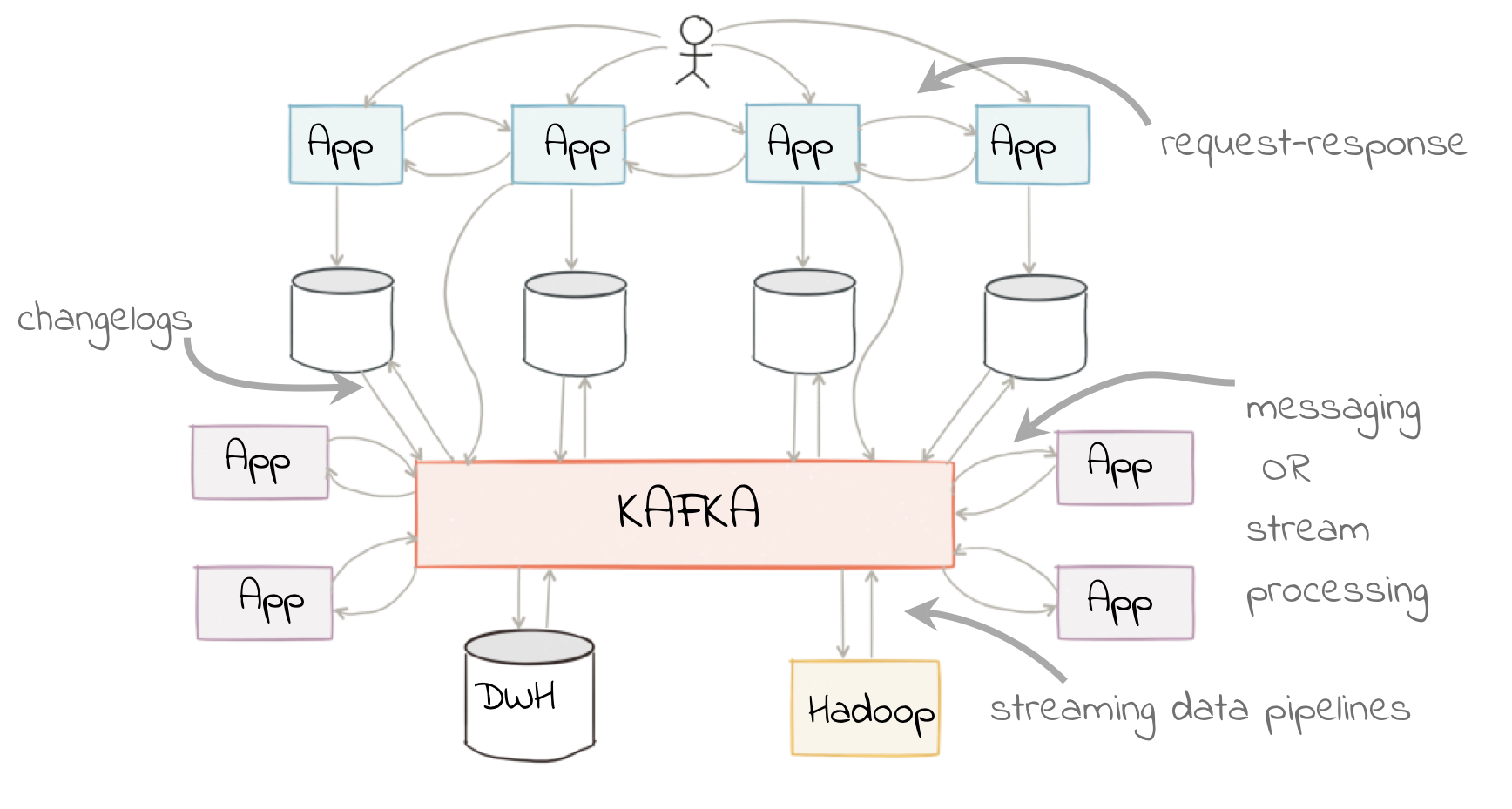
Let’s see what the above e-commerce example looks like in practice when implemented using a more modern design pattern, based on an event streaming platform. We’re going to use the open source Apache Kafka® and KSQL project to do this. KSQL is the streaming SQL engine for Apache Kafka, implemented on top of the Kafka Streams API, which is part of Apache Kafka itself.
In our example, the events are the reviews that the users submit on the site, and these are streamed directly into Kafka. From here, they can be joined to the user information in real time with the resulting enriched data written back to Kafka. With this transformation done, the data can be used to drive the dependant applications and targets. The transformation logic is only required once, and the data is extracted from the source system only once. The transformed data can be used multiple times by independent applications. New sources and targets can be added without any change to the existing components. All of this is very low latency.
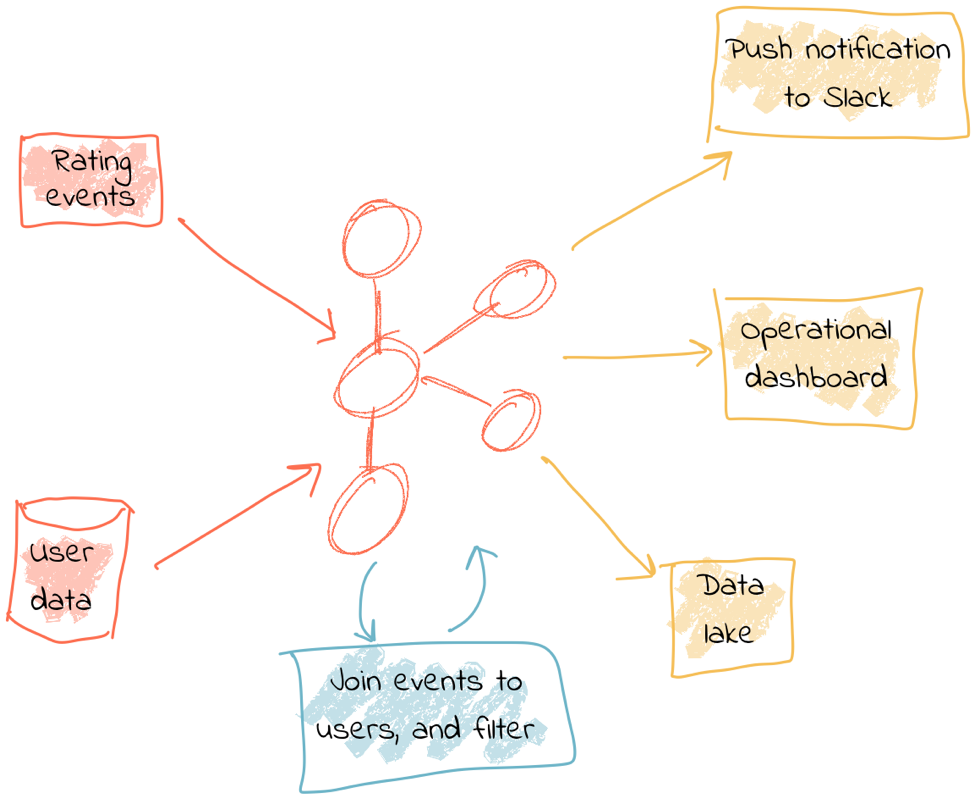
At a high level, the design looks like this:
- Web application emits review directly to Kafka
- Kafka Connect streams snapshot of user data from database into Kafka and keeps it directly in sync with change data capture
- Stream processing adds user data to the review event and writes it back to a new Kafka topic
- Stream processing filters the enriched Kafka topic for poor reviews from VIP users and writes to a new Kafka topic
- Event-driven application listens to a Kafka topic and pushes notifications as soon as a VIP user leaves a poor review
- Kafka Connect streams the data to Elasticsearch for an operational dashboard
- Kafka Connect streams the data to S3 for long-term ad hoc analytics and use alongside other datasets
The benefits include:
- Data enrichment occurs once and the enriched data is available for any consuming application
- Processing is low latency
- Notifications to the customer ops team happen as soon as the VIP customer leaves a poor review, leading to a much better customer experience and higher chance of retaining their business
- Ability to scale easily by adding new nodes as required for greater throughput
So building an ETL pipeline that incorporates stream processing is a useful process when using Kafka. ETL has needed to change due to the inclusion of real-time data. All the data that is written needs to be extracted, transformed and loaded immediately.
To build streaming ETL with Kafka requires four steps. The first extracts the data into Kafka. The second pulls data from Kafka topics. Third, the data is transformed in KStream object. Finally, the data is loaded to other systems.
Transform once, use many
Often the data used by one system will also be required by another, and the same goes for data that has been through enrichment or transformation. The work that we do to cleanse the inbound stream of customer details, such as standardizing the country name, state/county identifiers and phone number formatting—all of this is useful to both the analytics platform downstream as well as any other application that deals with customer data. We can formalize this into a three-tier data model applicable to many data processing architectures. Tier 1 is the raw data. Tier 2 is the integration layer, where data is clean and standardized, available for anyone to analyze. Tier 3 is the application layer, in which data is joined, aggregated and formatted in a way that maximizes its usefulness for the needs of a specific application.
A great pattern to adopt is to stream raw data (Tier 1) as it is transformed (Tier 2) back into Kafka. This makes that data available in real time to all applications directly. The alternative is the legacy pattern of writing transformed data down to a target (often a data lake) and having other applications pull the data from there—with the associated latency and complication to our systems architecture. Where applications come to consume and transform the data for their own purpose (Tier 3), this can also be done in Kafka. Depending on technical requirements, using other technologies such as NoSQL, RDBMS or object storage may be required.
By streaming the transformed data back into Kafka, we receive some great advantages:
- Separation of responsibilities between the transformation and application/system consuming that data: The latency remains low, as the transformed data that is streamed to Kafka can be streamed straight to the desired target. Even for a transformation in which you think only your application will want the transformed data, this pattern is a useful one.
- Transformed data can be used to drive other applications: Because Kafka persists data, the same data can be used by multiple consumers—and completely independently. Unlike traditional message queues, data is not removed from Kafka once it has been consumed.
- Single instance of the transformation code: This instance includes any associated business logic that it implements. That means a single place in which to maintain it, a standard definition for any measures derived and consistency in the data across systems. Contrast this with multiple systems each performing the same transformation logic. For the best will in the world, the code will diverge, and you will end up hunting for that needle in a haystack of why your data doesn’t reconcile between systems.
The goal is to avoid creating 1:1 pipelines and instead create a hub with the platform at the center. Traditionally, ETL would be done on a point-to-point basis, taking data from a source system and loading it to a target one. If the data was needed elsewhere it would either be extracted twice or taken from the original target. Both of these are undesirable. The former increases the load on the source system, and the latter introduces an unnecessary dependency and coupling in the design. In short, this is how the “big-ball-of-mud” or “spaghetti” architectures start.
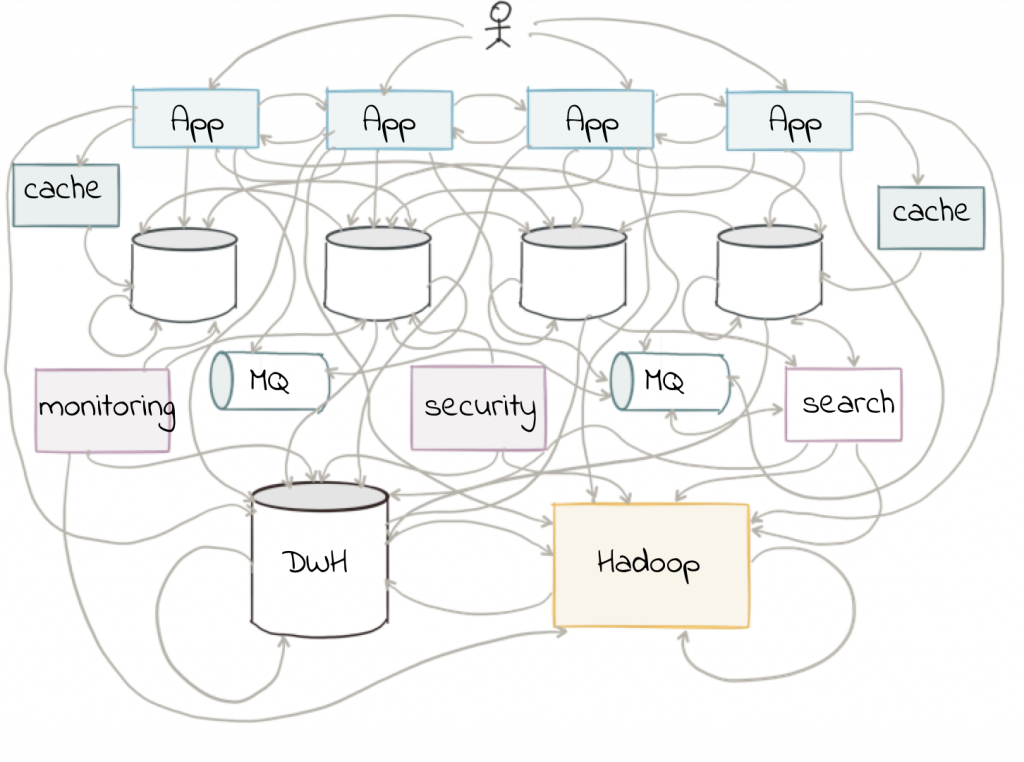
By adopting an event streaming platform, we decouple the sources and targets for data, and thus introduce greater flexibility to build upon and evolve an architecture.
Let’s build it!
So far, we’ve just looked at the theory behind an event streaming platform and why one should consider it as a core piece of architecture in a data system. To learn more, you can read my InfoQ article Democratizing Stream Processing with Apache Kafka and KSQL, which builds on the concepts in this blog post and provides a tutorial for building out the e-commerce example described above. You may like to also check out the following resources:
- Watch the online talk ETL is Dead; Long Live Streams
- Download Confluent Platform and follow the quick start
- Learn about ksqlDB, the successor to KSQL
Get started with Confluent, for free
Watch demo: Kafka streaming in 10 minutes
Avez-vous aimé cet article de blog ? Partagez-le !
Abonnez-vous au blog Confluent



Introducing Versioned State Store in Kafka Streams
Versioned key-value state stores, introduced to Kafka Streams in 3.5, enhance stateful processing capabilities by allowing users to store multiple record versions per key, rather than only the single latest version per key as is the case for existing key-value stores today...


Delivery Guarantees and the Ethics of Teleportation
This blog post discusses the two generals problems, how it impacts message delivery guarantees, and how those guarantees would affect a futuristic technology such as teleportation.