[Webinar] Harnessing the Power of Data Streaming Platforms | Register Now
Automatic Observer Promotion Brings Fast and Safe Multi-Datacenter Failover with Confluent Platform 6.1
Get started with Confluent, for free
Watch demo: Kafka streaming in 10 minutes
Persisting data in multiple regions has become crucial for modern businesses: They need their mission-critical data to be protected from accidents and disasters. They can achieve this goal by running a single Apache Kafka® cluster across multiple datacenters (DCs) with synchronous replication. This setup makes disaster recovery easy: Client applications fail over automatically and avoid any sort of data ordering inconsistencies. As an alternative to this synchronous setup, Confluent Platform 5.4 introduced Multi-Region Clusters built directly into Confluent. Multi-Region Clusters created an asynchronous type of replica, called an observer. This allows operators to replicate their data both synchronously and asynchronously on a per-region and per-topic basis. Some of Confluent’s largest customers use observers for fast, easy failover during a datacenter outage.
However, the first release of Multi-Region Clusters required a manual process an operator would have to follow to fail over to an observer. Operators would have to run the “unclean leader election” command on the unavailable topic partition that they’d like to make available by promoting the observer to a leader. This could become cumbersome rather quickly, as unclean leader election would have to be run on every unavailable topic partition, and there could be hundreds or even thousands of them in the event of a disaster. All of these would have to be monitored and performed over the duration of the disaster. In addition, unclean leader elections could cause data loss. And once the failed datacenter came back online, operators would have to repeat this laborious process to restore their desired steady state.
All of this changes with the introduction of Automatic Observer Promotion in Confluent Platform 6.1. In the event of a replica failure, observers can now be automatically promoted to the in-sync replica (ISR) list should the replica set fall below the minimum required synchronous replicas (min.insync.replicas). This gives Kafka operators a fast, automatic, no-data-loss option for maintaining topic availability in the event of a failure in multi-datacenter stretch clusters. Now, we will more closely examine what an observer is, how previous versions of observers behaved, and what’s new and improved in 6.1.
What are observers?
When writing data to a partition in Kafka, the preferred producer configuration for data durability is acks=all. This causes the producer to wait until all members of the current ISR for a partition acknowledge the produced record(s) before sending more data to that partition. Once all of the replicas have successfully copied the record(s) to its logs, the high watermark, which is the offset of the last message that was successfully copied to all of the replicas in the ISR, is incremented. This is one of the ways that Kafka provides durability and availability. To operate a reliable stretch cluster with traditional synchronous replicas, the datacenters must be relatively close to each other and have very stable, low-latency, and high-bandwidth connections between the DCs.
Observers in Confluent Server are effectively asynchronous replicas. They replicate partitions from the leader just like the followers do, but they can never participate in the ISR or become a partition leader (unless the operator runs unclean leader election on an observer). What makes them asynchronous is the fact that they are never considered when incrementing the high watermark because they never join the ISR. This provides the following benefits:
- Relaxed physical distance and network requirements between DCs.
- Improved data durability without sacrificing throughput.
- Replication works across high-latency network connections with weak or unpredictable bandwidth. Since observers are effectively asynchronous replicas, this prevents them from falling in and out of sync with the ISR, also known as “ISR thrashing.”
- A complement to Follower Fetching: The ability for a consumer to read from a replica instead of a leader. Having an observer in the same region as the consumers will allow consumers to read more cost effectively from the locally placed observer instead of trying to consume over the expensive high-latency network connection.
- Disaster recovery benefits, such as automatic client failover.
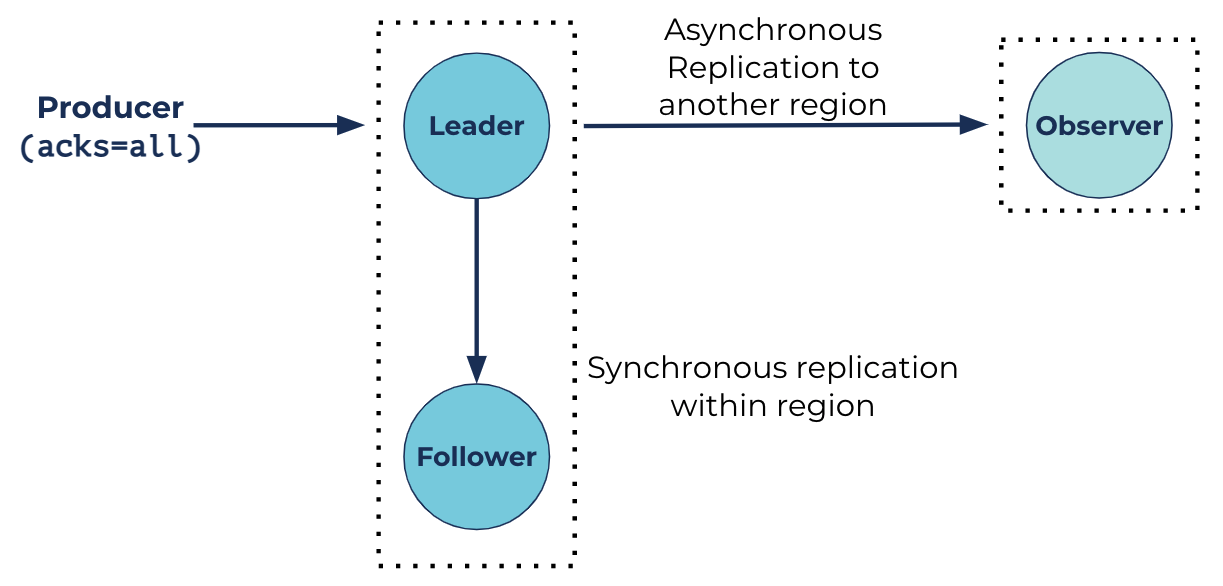
The old: Manually failing over observers prior to Confluent Server 6.1
Observers used to differ from replicas in that they would not join the ISR list that is used to determine a partition’s availability. Prior to Automatic Observer Promotion, an observer would only be able to join this list with manual intervention. This could be automated by looking at JMX metrics and a background task running somewhere, but who has time for that?
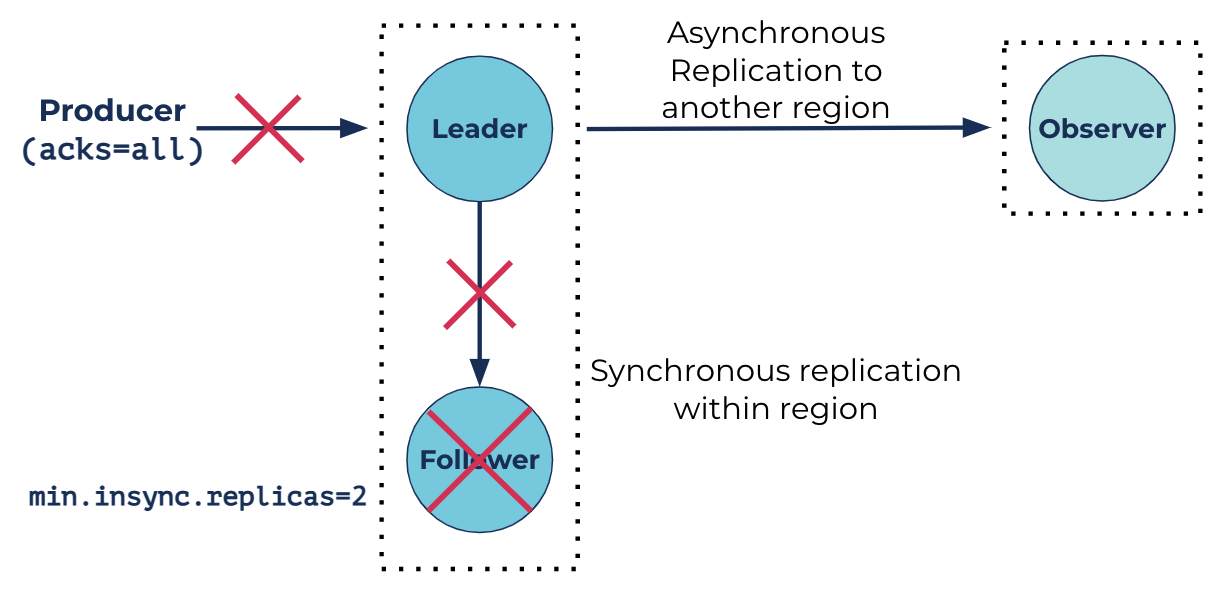
In the diagram above, we see that the follower replica has failed. Notice how the topic partition is configured to have min.insync.replicas=2. The durability limits of a particular topic partition is determined by its min.insync.replicas configuration. Taking the example above, a min.insync.replicas value of two requires that there are a minimum of two replicas in the ISR list for a producer with the configuration of acks=all to be able to produce to the partition. Since the follower replica has now failed, this will mean that the partition will be taken offline and drastically impact client applications. With manual intervention by the operator, the observer can be elected leader through unclean leader election and the partition can come back online (since the min.insync.replicas=2 requirement is met) and be produced to.
While electing observers as leader through unclean leader election provides the ability to mitigate the initial disaster, it presents two big problems: Manual intervention is operationally very tedious (and the partition remains offline until the manual process is completed), and running unclean leader election may result in data loss. A better solution in the example illustrated above would be to temporarily promote the observer into the ISR list to satisfy the min.insync.replicas requirement so that the client applications can still produce to the partition while the failed replica can be recovered. Once the replica has recovered, the observer should then be demoted from the ISR to the observer set. With Automatic Observer Promotion, we can do just that. When an observer is promoted to the ISR, it is still considered an observer, only it is part of the ISR and needs to acknowledge the records being produced synchronously, just like the other replicas in the replica set.
Manual intervention is always more error prone and can become operationally tedious when the number of partitions to fail over to observers grows to be very large. More dangerously, unclean leader election presents the possibility for data loss. In an unclean leader election, it is possible for the new leader not to have all of the produced records up to the high watermark. This can result in the truncation of all the topic partitions to an offset that is before the high watermark. In the case of observers, if not promoted quickly enough, then any future failures will cause data loss and partition unavailability for both producers and consumers. Most outages are rolling: The situation can go from bad to worse over time. To minimize this possible data loss, operators would have to monitor the observer lag to ensure it was not falling too far behind, thus putting more operational burden on an already operationally intensive and error-prone task.
The new: Automatically failing over observers in Confluent Server 6.1
As highlighted in the previous section, prior to 6.1 the observer failover process was manual, tedious, and had a potential for data loss. With the introduction of Automatic Observer Promotion in 6.1, the promotion and demotion of observers is completely automatic and doesn’t risk availability and data loss. Let’s take a look at how it works.
When a partition falls below the min.insync.replicas configuration, a producer configured with acks=all is no longer able to produce to the partition. Under these circumstances, with Automatic Observer Promotion a caught-up observer will be picked to be promoted to the ISR list. This will restore availability to the partition and allow producers to once again produce data. During this time, the observer acts as a synchronous replica: It must receive data before a producer can move on. Once the failed replica comes back online and joins the ISR list, the promoted observer will be automatically demoted out of the ISR list and will once again become an asynchronous replica.
Automatic promotion and automatic demotion removes the need for manual intervention. Observers will only be promoted if sufficiently caught up, and a promotion will occur as soon as a partition falls below the min.insync.replicas requirement. In addition, it eliminates the risks of unclean leader election. By preserving the leader of the partition, no offsets are truncated while allowing the observer to be written to synchronously and preserving availability. This empowers operators to achieve a recovery point objective (RPO) of zero when properly configured, while maintaining a low recovery time objective (RTO).
The behavior for when to automatically promote observers is controlled by the observerPromotionPolicy field in a topic’s replica placement policy. The replica placement policy controls not only the behavior for when observers should be promoted but also how the replicas in a topic should be placed. This allows flexibility in giving some, more critical topics higher availability than others. It can have the following values:
- under-min-isr: Observers will be automatically promoted if the ISR size drops below the topic’s min.insync.replicas configuration. For instance, given a partition with three sync replicas and min.insync.replicas=2, an observer would be promoted if two of the synchronous replicas had failed. This is also the default observerPromotionPolicy.
- under-replicated: Observers will be automatically promoted if the ISR size drops below the configured count of replicas in the topic’s replica placement policy. For instance, given a partition with three sync replicas and min.insync.replicas=2, an observer would be promoted if one replica had failed.
- leader-is-observer: Observers will only be automatically promoted if the current partition leader is an observer. This configuration is equivalent to the functionality that existed prior to Confluent Platform 6.1.
Automatic Observer Promotion is activated by changing the version of the replica placement policy to two.
Let’s walk through an example for Automatic Observer Promotion with a 2.5 DC architecture. A 2.5 DC architecture is defined as having a single Kafka cluster stretch between two separate datacenters and a “0.5” datacenter having a ZooKeeper node. The “0.5” datacenter is needed to avoid a “split-brain” scenario between the two DCs: a network partition such that the two datacenters are no longer able to communicate with each other but can still communicate with their client applications. Having the additional ZooKeeper node gives quorum between the two DCs as the tiebreaker. A 2.5 DC deployment is an excellent architecture for production use cases where high availability and data durability are critical. More information about the 2.5 DC architecture can be found in this Kafka Summit 2020 talk titled A Tale of Two Datacenters: Kafka Streams.
Say we have the following replica placement policy:
{
"version": 2,
"replicas": [
{
"count": 2,
"constraints": {
"rack": "New York A"
}
},
{
"count": 2,
"constraints": {
"rack": "Boston A"
}
}
],
"observers": [
{
"count": 1,
"constraints": {
"rack": "New York B"
}
},
{
"count": 1,
"constraints": {
"rack": "Boston B"
}
}
],
"observerPromotionPolicy":"under-min-isr"
}
In the replica placement policy, the rack defines where exactly we want to place the replicas and the count defines how many of those replicas we would like to place in that rack. In this example, we have placed two synchronous replicas each in Boston and New York and have placed one observer each in Boston and New York. A partition with this placement policy would look something like this:
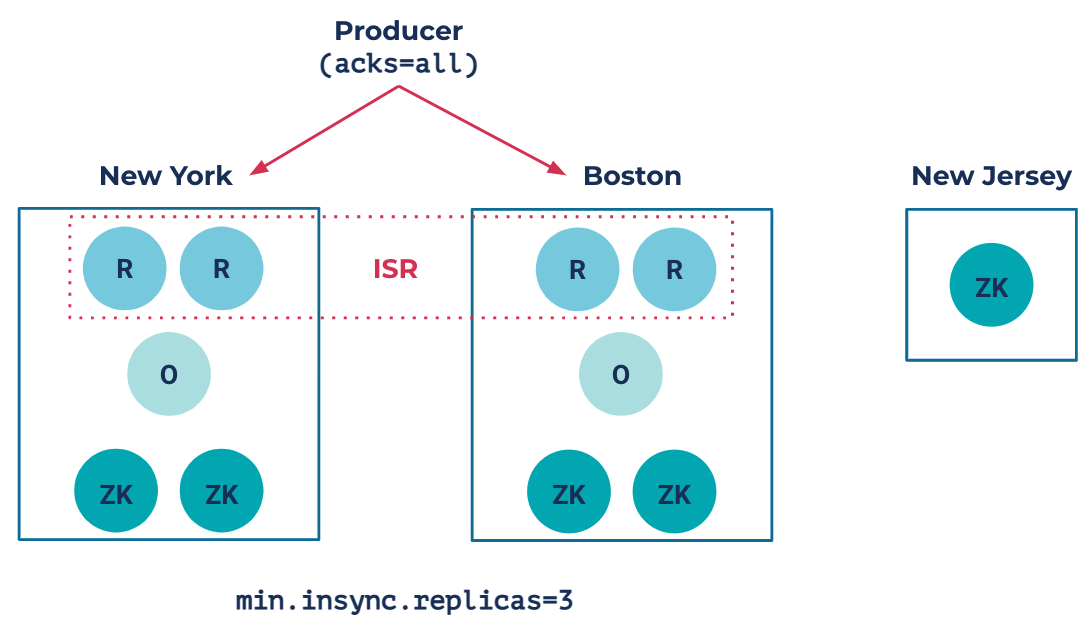
Notice in this setup that min.insync.replicas=3. This forces data from the producer to go to both datacenters in New York and Boston, providing strong consistency between the two DCs and making the data extra durable. In this situation, the observers will stay out of the ISR and replicate asynchronously.
Let’s say that a disaster occurs, forcing the Boston DC to go offline. Automatic Observer Promotion would kick into action, and the resulting promotion would look something like this:
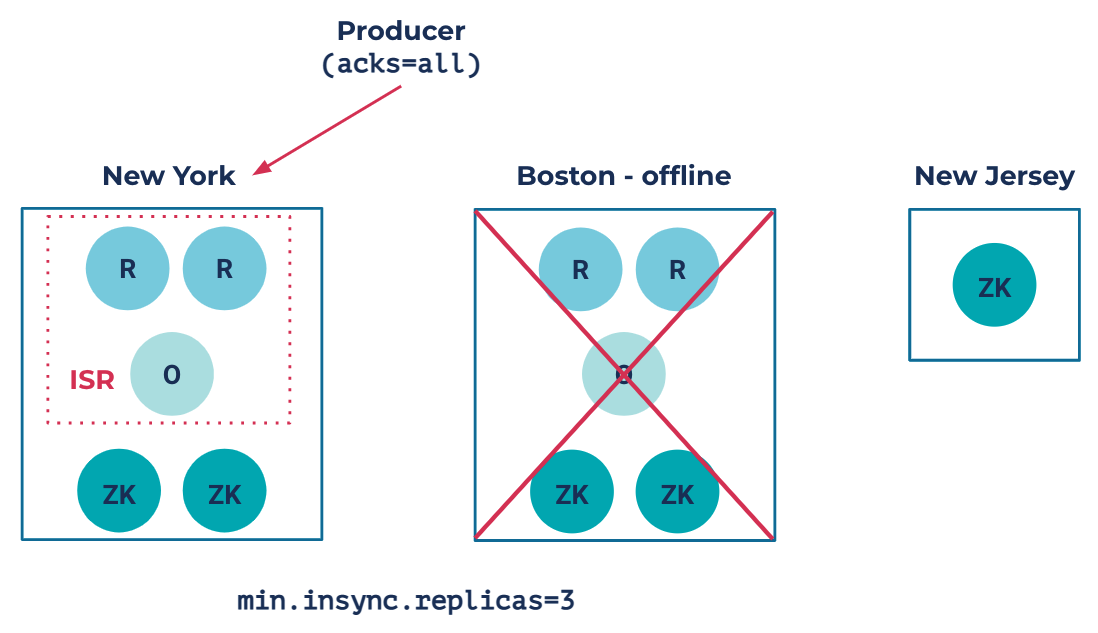
Since the Boston DC has gone offline, the partition has lost two out of its four synchronous replicas. As a result, it has fallen under the min.insync.replicas=3 requirement. Because the observerPromotionPolicy is under-min-isr, Automatic Observer Promotion kicks in and promotes the Observer in New York into the ISR. This satisfies the requirement of min.insync.replicas=3 and allows produce requests to go through. The observer’s automatic promotion maintains the partition’s availability. All clients will automatically fail over to New York without any custom code or tooling. Failback is automatic too. Once the Boston DC comes back online and catches up with the New York replicas, the observer will be automatically demoted and the cluster will return to the previous steady state.
Monitoring observers in Confluent Server
While Automatic Observer Promotion greatly reduces the need for operator intervention, operators should still monitor important information about the health of Observers and the overall Confluent Server deployment. A few of the important JMX metrics to look out for are these:
- kafka.cluster:type=Partition,name=InSyncReplicasCount,topic=,partition=: The number of replicas in the ISR.
- kafka.cluster:type=Partition,name=CaughtUpReplicasCount,topic=<topic=name>,partition=: The number of replicas that are considered caught up to the topic partition leader; this may be greater than the size of the ISR as observers may be caught up but not part of the ISR.
- kafka.cluster:type=Partition,name=ObserversInIsrCount,topic=,partition=: The number of observers that are currently in the ISR; this will be important to look out for when using Automatic Observer Promotion as this will indicate if observers have been promoted in the case of a replica failure
More information about other JMX metrics relevant to observers can be found in the documentation.
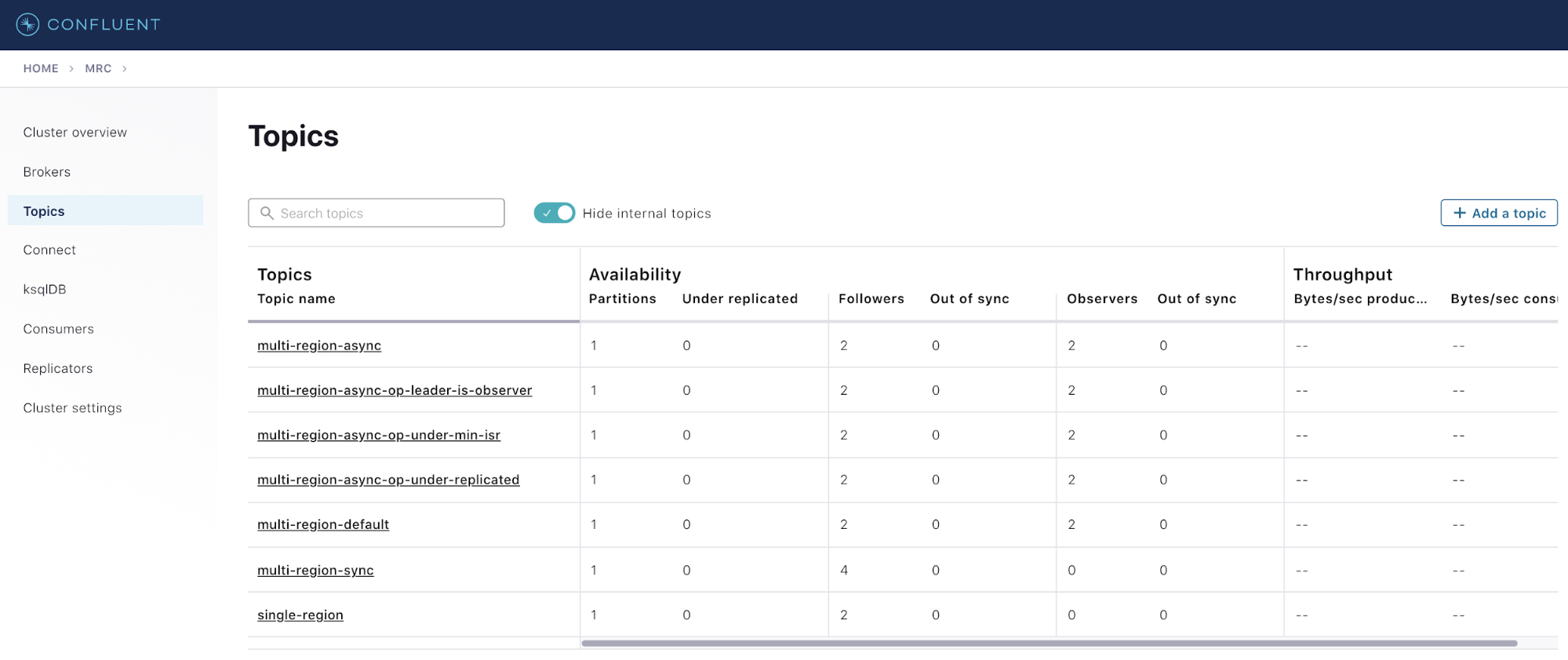
Operators can also look at the health of their Confluent Server deployment by using Confluent Control Center. In the “Topics” tab, you can have a bird’s-eye view of the health of each topic and the state of the replicas and observers associated with each topic.
Conclusion
Multi-Region Clusters, introduced in Confluent Server 5.4, enabled you to run a single Kafka cluster across multiple regions in a cost-effective and streamlined way by adding asynchronous replicas. Automatic Observer Promotion in Confluent Platform 6.1 goes a step further by reducing the need for manual intervention while minimizing the impact of data loss and partition availability due to failover. It provides an automatic way to failover and failback—all while providing an RPO of zero.
Want to learn more?
- Listen to the podcast episode Resurrecting In-Sync Replicas with Automatic Observer Promotion ft. Anna McDonald
- See the Confluent Platform 6.1 documentation to get started
- Try the tutorial for Multi-Region Clusters and Automatic Observer Promotion
Automatic Observer Promotion would not be possible without our wonderful team of distributed systems engineers, product managers, solution engineers, and customer success architects, who helped bring the feature from a concept to a reality: Thomas Scott, Anna McDonald, Chris Matta, Jose Garcia Sancio, Addison Huddy, Luke Knepper, Nikhil Bhatia, Yeva Byzek, and the entire Kafka team at Confluent.
Get started with Confluent, for free
Watch demo: Kafka streaming in 10 minutes
Avez-vous aimé cet article de blog ? Partagez-le !
Abonnez-vous au blog Confluent



Schema Registry Clients in Action
Learn about the bits and bytes of what happens behind the scenes in the Apache Kafka producer and consumer clients when communicating with the Schema Registry and serializing and deserializing messages.

How to Securely Connect Confluent Cloud with Services on Amazon Web Services (AWS), Azure, and Google Cloud Platform (GCP)
The rise of fully managed cloud services fundamentally changed the technology landscape and introduced benefits like increased flexibility, accelerated deployment, and reduced downtime. Confluent offers a portfolio of fully managed...