Introducing Connector Private Networking: Join The Upcoming Webinar!
Apache Kafka Producer Improvements with the Sticky Partitioner
Get started with Confluent, for free
Watch demo: Kafka streaming in 10 minutes
The amount of time it takes for a message to move through a system plays a big role in the performance of distributed systems like Apache Kafka®. In Kafka, the latency of the producer is often defined as the time it takes for a message produced by the client to be acknowledged by Kafka. As the old saying goes, time is money, and it is always best to reduce latency when possible in order for the system to run faster. When the producer is able to send out its messages faster, the whole system benefits.
Each Kafka topic contains one or more partitions. When a Kafka producer sends a record to a topic, it needs to decide which partition to send it to. If we send several records to the same partition at around the same time, they can be sent as a batch. Processing each batch requires a bit of overhead, with each of the records inside the batch contributing to that cost. Records in smaller batches have a higher effective cost per record. Generally, smaller batches lead to more requests and queuing, resulting in higher latency.
A batch is completed either when it reaches a certain size (batch.size) or after a period of time (linger.ms) is up. Both batch.size and linger.ms are configured in the producer. The default for batch.size is 16,384 bytes, and the default of linger.ms is 0 milliseconds. Once batch.size is reached or at least linger.ms time has passed, the system will send the batch as soon as it is able.
At first glance, it might seem like setting linger.ms to 0 would only lead to the production of single-record batches. However, this is usually not the case. Even when linger.ms is 0, the producer will group records into batches when they are produced to the same partition around the same time. This is because the system needs a bit of time to handle each request, and batches form when the system cannot attend to them all right away.
Part of what determines how batches form is the partitioning strategy; if records are not sent to the same partition, they cannot form a batch together. Fortunately, Kafka allows users to select a partitioning strategy by configuring a Partitioner class. The Partitioner assigns the partition for each record. The default behavior is to hash the key of a record to get the partition, but some records may have a key that is null. In this case, the old partitioning strategy before Apache Kafka 2.4 would be to cycle through the topic’s partitions and send a record to each one. Unfortunately, this method does not batch very well and may in fact add latency.
Due to the potential for increased latency with small batches, the original strategy for partitioning records with null keys can be inefficient. This changes with Apache Kafka version 2.4, which introduces sticky partitioning, a new strategy for assigning records to partitions with proven lower latency.
Sticky partitioning strategy
The sticky partitioner addresses the problem of spreading out records without keys into smaller batches by picking a single partition to send all non-keyed records. Once the batch at that partition is filled or otherwise completed, the sticky partitioner randomly chooses and “sticks” to a new partition. That way, over a larger period of time, records are about evenly distributed among all the partitions while getting the added benefit of larger batch sizes.
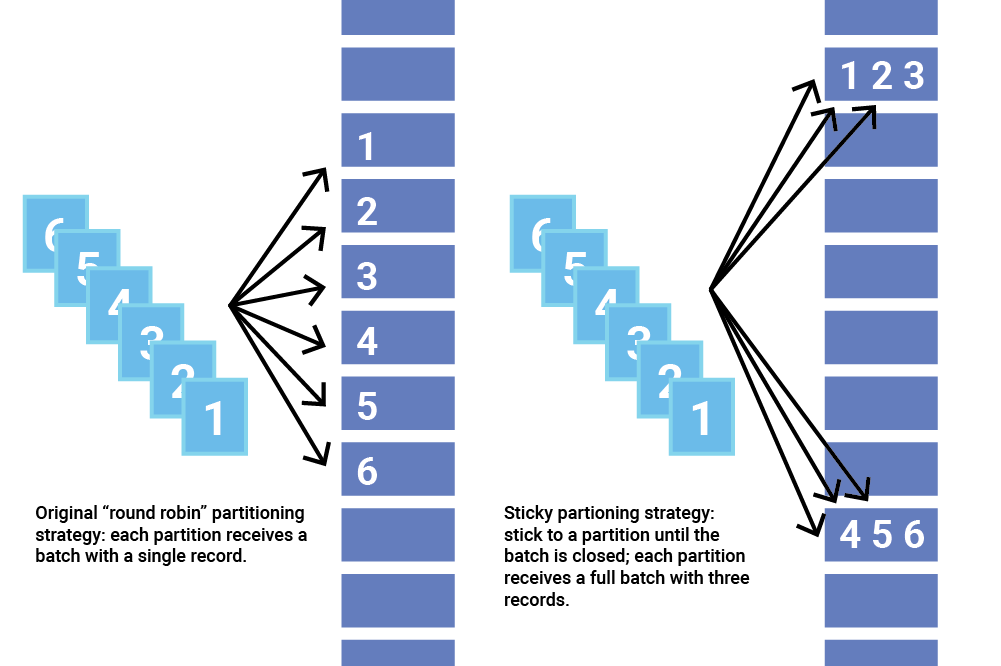
In order to change the sticky partition, Apache Kafka 2.4 also adds a new method called onNewBatch to the partitioner interface for use right before a new batch is created, which is the perfect time to change the sticky partition. DefaultPartitioner implements this feature.
Basic tests: Producer latency
It’s important to quantify the impact of our performance improvements. Apache Kafka provides a test framework called Trogdor that can run different benchmarks, including one that measures producer latency. I used a test harness called Castle to run ProduceBench tests using a modified version of small_aws_produce.conf. These tests used three brokers and 1–3 producers and ran on Amazon Web Services (AWS) m3.xlarge instances with SSD.
Most of the tests included ran with the specifications below, and you can modify the Castle specification by replacing the default task specification with this example task spec. Some tests ran with slightly different settings, and those are mentioned below.
| Duration of test | 12 minutes |
| Number of brokers | 3 |
| Number of producers | 1–3 |
| Replication factor | 3 |
| Topics | 4 |
| linger.ms | 0 |
| acks | all |
| keyGenerator | {"type":"null"} |
| useConfiguredPartitioner | true |
| No flushing on throttle (skipFlush) | true |
In order to get the best comparison, it is important to set the fields useConfiguredPartitioner and skipFlush in taskSpecs to true. This ensures that the partitions are assigned with the DefaultPartitioner and that batches are sent not through flushing but through filled batches or linger.ms triggering. Of course, you should set the keyGenerator to only generate null keys.
In almost all tests comparing the original DefaultPartitioner to the new and improved sticky version, the latter (sticky) had equal or less latency than the original DefaultPartitioner (default). When comparing the 99th percentile (p99) latency of a cluster with three producers that produced 1,000 messages per second to topics with 16 partitions, the sticky partitioning strategy had around half the latency of the default strategy. Here are the results from three runs:
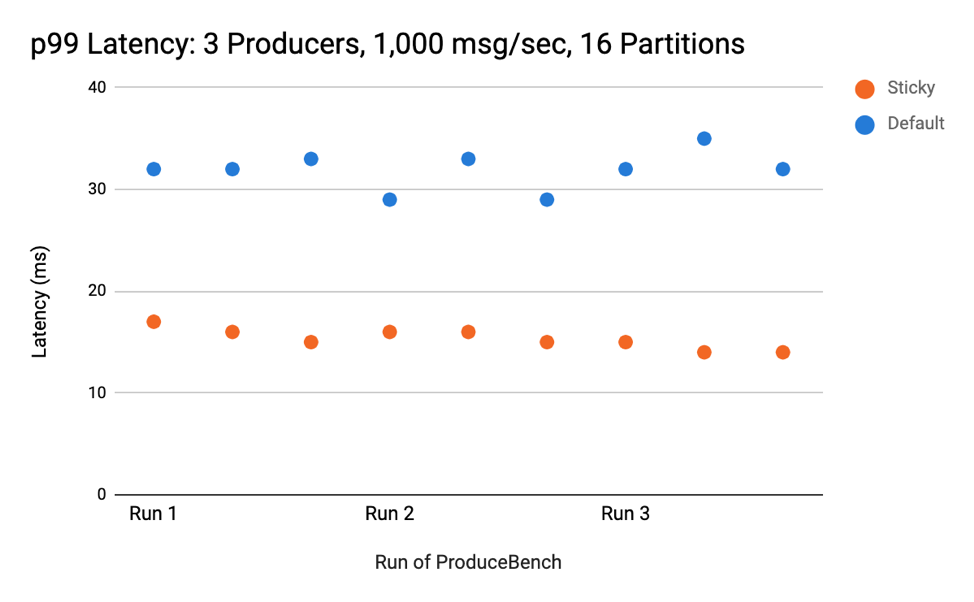
The decrease in latency became more apparent as partitions increased, in line with the idea that a few larger batches result in lower latency than many small batches. The difference is noticeable with as few as 16 partitions.
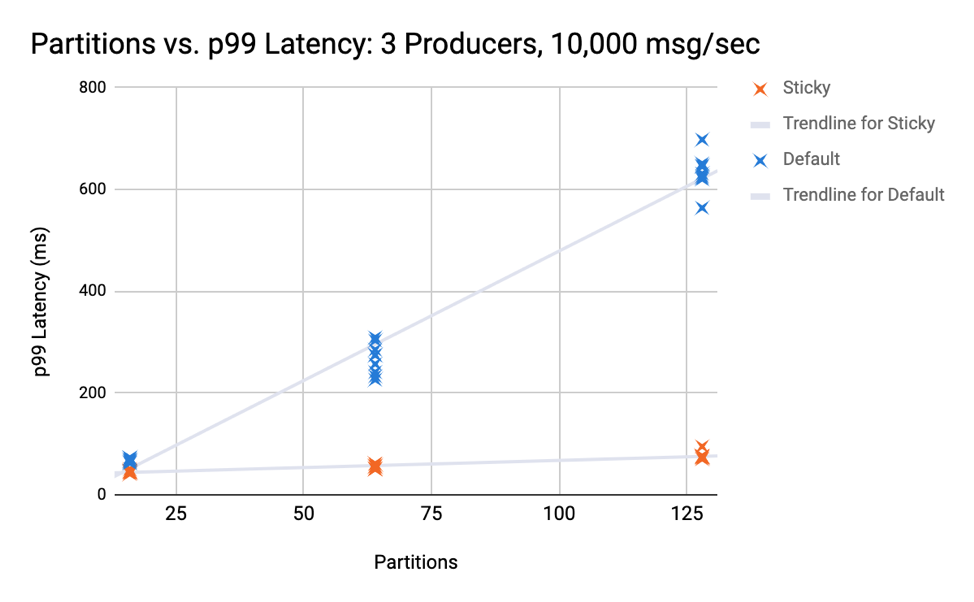
The next set of tests kept three producers producing 10,000 messages per second constant but increased the number of partitions. The graph below shows the results for 16, 64, and 128 partitions, indicating that the latency from the default partitioning strategy increases at a much faster rate. Even in the case with 16 partitions, the average p99 latency of the default partitioning strategy is 1.5x that of the sticky partitioning strategy.
Linger latency tests and performance with different keys
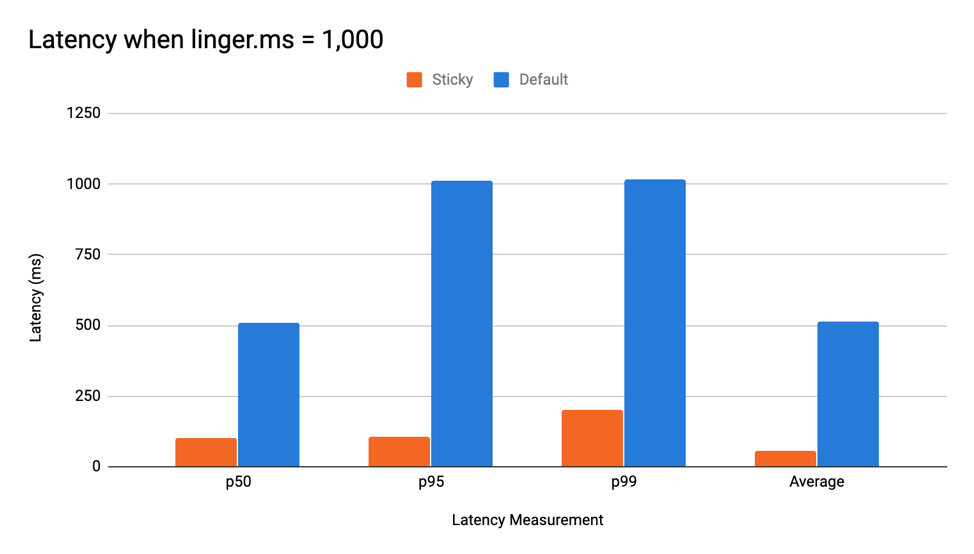
As mentioned earlier, waiting for linger.ms can inject latency into the system. The sticky partitioner aims to prevent this by sending all records to one batch and potentially filling it earlier. Using the sticky partitioner with linger.ms > 0 in a relatively low-throughput scenario can mean incredible reductions in latency. When running with one producer that sends 1,000 messages per second and a linger.ms of 1,000, the p99 latency of the default partitioning strategy was five times larger. The graph below shows the results of the ProduceBench test.
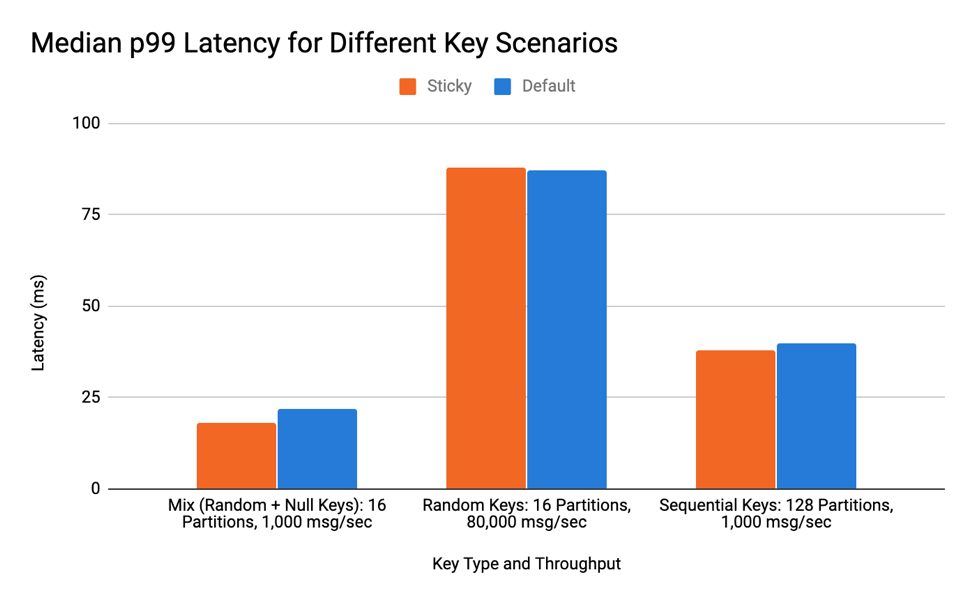
The sticky partitioner helps improve the client’s performance when producing keyless messages. But how does it perform when the producer generates a mix of keyless and keyed messages? A test with randomly generated keys and a mixture of keys and no keys revealed that there is no significance difference in latency.
In this scenario, I examined a mixture of random and null keys. This sees slightly better batching, but since keyed values ignore the sticky partitioner, the benefit is not very significant. The graph below shows the median p99 latency of three runs. Over the course of testing, the latency did not drastically differ, so the median provides an accurate representation of a “typical” run.
The second scenario tested was random keys in a high-throughput situation. Since implementing the sticky partitioner changed the code slightly, it was important to see that running through the bit of extra logic would not affect the latency to produce. Since no sticky behavior or batching occurs here, it makes sense that the latency is roughly the same as the default. The median result of the random key test is shown in the graph below.
Finally, I tested the scenario that I thought would be worst for the sticky partition implementation—sequential keys with a high number of partitions. Since the extra bit of logic occurs near the time new batches are created, and this scenario creates a batch on virtually every record, checking that this did not cause an increase in latency was crucial. As the graph below shows, there was no significant difference.
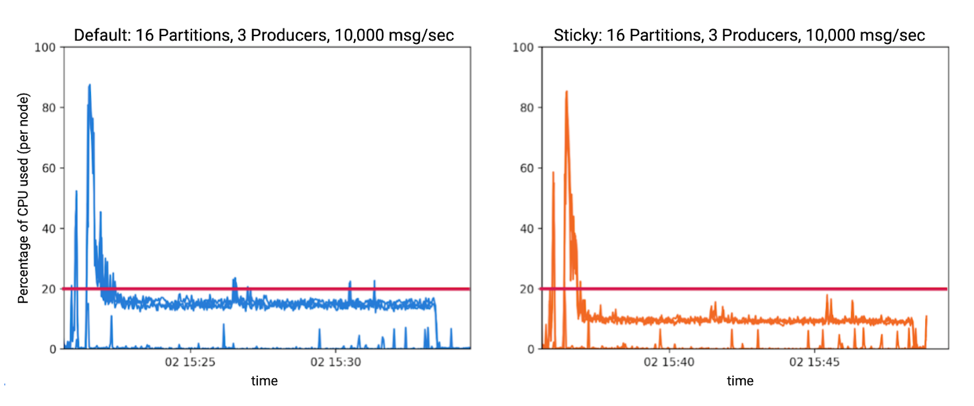
CPU utilization for producer bench tasks
When performing these benchmarks, one thing to note is that the sticky partitioner decreased CPU usage in many cases.
For example, when running three producers producing 10,000 messages per second to 16 partitions, a noticeable drop in CPU usage was observed. Each line on the graphs below represents the percentage of CPU used by a node. Each node was both a producer and a broker, and the lines for the nodes are superimposed. This decrease in CPU was seen in tests with more partitions and with lower throughput as well.
Sticking it all together
The main goal of the sticky partitioner is to increase the number of records in each batch in order to decrease the total number of batches and eliminate excess queuing. When there are fewer batches with more records in each batch, the cost per record is lower and the same number of records can be sent more quickly using the sticky partitioning strategy. The data shows that this strategy does decrease latency in cases where null keys are used, and the effect becomes more pronounced when the number of partitions increases. In addition, CPU usage is often decreased when using the sticky partitioning strategy. By sticking to a partition and sending fewer but bigger batches, the producer sees great performance improvements.
And the best part is: this producer is simply built into Apache Kafka 2.4!
If you’d like, you can also download the Confluent Platform to get started with the leading distribution of Apache Kafka.
Get started with Confluent, for free
Watch demo: Kafka streaming in 10 minutes
Avez-vous aimé cet article de blog ? Partagez-le !
Abonnez-vous au blog Confluent



Kafka-docker-composer: A Simple Tool to Create a docker-compose.yml File for Failover Testing
The Kafka-Docker-composer is a simple tool to create a docker-compose.yml file for failover testing, to understand cluster settings like Kraft, and for the development of applications and connectors.


How to Process GitHub Data with Kafka Streams
Learn how to track events in a large codebase, GitHub in this example, using Apache Kafka and Kafka Streams.