[Webinar] Harnessing the Power of Data Streaming Platforms | Register Now
Apache Kafka: Getting Started
Get started with Confluent, for free
Watch demo: Kafka streaming in 10 minutes
Seems that many engineers have “Learn Kafka” on their new year resolution list. This isn’t very surprising. Apache Kafka is a popular technology with many use-cases. Armed with basic Kafka knowledge an engineer can add a message bus to his or her application, integrate applications and data stores, build stream processing systems, and set out to build a scalable and fault tolerant microservices architecture. Not bad payoff for learning one simple framework. A recent report listed Apache Kafka as one of the top 10 in demand skills in the market today. So if you are an engineer who wants to separate yourself from your peers, Kafka is worth a look.

So, how does one go about learning Apache Kafka? The short answer is, it depends. Depending on your role, there are several ways you can get started with Kafka and we’ll outline those below. There are some things that are applicable to everyone, though, so let’s start there:
The first step is to download Kafka. Confluent takes the guesswork out of getting started with Kafka by providing a commitment free download of the Confluent distribution. The Confluent distribution has not only been certified with the latest capabilities that come with Apache Kafka but also includes add-ons that make Kafka more robust, including a REST Proxy, several connectors, and a schema registry.
Once you have the tar.gz file you can install Kafka just by unzipping the file somewhere convenient. Or, you can install an RPM or DEB file following the instructions here.
Apache Kafka is a Streaming Platform and at its core is a pub-sub message bus, so you will want to start by creating few topics, producing messages to the topics and subscribing to the topics to consume events. The best way to learn to do that is with the quickstart guide — you can skip step 1, since we already did that.
Congratulations, you successfully published and subscribed messages to Kafka! Before going much further, I recommend taking an hour or two and read the Kafka design doc, sections 4.1 to 4.7 — this will help you understand the terminology and concepts in the rest of the discussion.
Now, obviously simply publishing and subscribing to a few messages is not how you’ll do things in a real system. First, you probably ran just a single Kafka broker – production systems typically run at least 3 brokers for high availability. Second, you published and subscribed using a command line tool. In production, you’ll either publish and subscribe using your own applications, or you may use connectors to integrate with external systems.
Now let’s look at which next steps make sense based on your role in the organization.
Software Engineer
As a software engineer, you probably have a favorite programming language, so the first step would be to find a great client for Kafka in your favorite language. Apache Kafka’s wiki has a comprehensive list of available clients.

Choosing a good client can be a topic for its own blog post, but in the absence of that we recommend picking a client that is based on either the Apache Kafka Java clients or librdkafka. These clients tend to support more of the Kafka protocol (i.e. more features), be more standardized (i.e. Kafka’s documentation and StackOverflow responses tend to apply), have better performance and be more reliable (due to extensive testing). Regardless of what you pick, we recommend that you check that there is an active community maintaining it — Kafka changes quickly and you don’t want to get left behind on new features. Looking at the github commits and issues to see community activity is a great way to figure this out.
Once you picked a client, you probably want to poke around its examples (if there are no examples, rethink your choice of clients) – make sure you can compile and run the examples, so you’ll know you have everything installed and configured correctly. Then you can check your understanding of the client APIs by modify the examples and looking at the results.
From there, the next step is to pick a small project to try writing yourself. The first project is usually a producer that produces a sequence of integers to a partition and a consumer that makes sure it got all of them. I have few other favorites: Clickstream sessionization, rule-based fraud detection in a stream of transactions, Kafkacat clone or top hashtags on a stream of tweets. Your first project is where you learn the most about the APIs and explore different ways to use them. The client documentation usually covers quite a bit, but if you just can’t figure out how to do something – Apache Kafka mailing lists or StackOverflow are both good places to ask for advice.
The next important step is to learn to configure clients for reliability and performance. Go over the Kafka documentation to understand the different client configurations that can affect reliability and performance, and then start playing around a bit. Configure a producer to acks=0, bounce few brokers, check what happens. Try acks=-1 and try again. How many messages get lost while bouncing? Do you understand why? Are messages still lost with acks=-1? What’s performance like? What happens if you increase the batch.size or linger.ms? There are lots of configs to play with, so I’d recommend starting with those marked as “high importance” in the Kafka documentation.
Once you have a favorite client, you learned its APIs with few sample problems and you experimented with the configurations and some failure conditions – you are ready to work on real world applications.
If you are a Java developer, you may want to continue and explore the advanced Streams APIs that are part of Apache Kafka. These allow you to not only produce or consume messages, but also perform advanced operations like window aggregations and joining streams. You can start by reviewing the docs and then exploring some examples.
Sysadmin / Site Reliability Engineer (SRE) / Ops
As an SRE, your goal is to learn to manage production Kafka systems. So to start, you need a somewhat more realistic Kafka environment. Start by running a 3-node cluster, the minimum recommended production system.
If you haven’t already – run step 6 of the Apache Kafka quick start guide to install a multi-node cluster. You can also use Docker to run a multi-node Kafka cluster. The images are the same we use in production systems, so it is a good place to start.
Use the same bin/kafka-topics.sh script from the quickstart guide to create few topics with multiple partitions and multiple replicas.
Since half the battle of successful production deployments is good monitoring, I’d recommend monitoring Kafka as the next step in setting up your environment. Kafka exposes many metrics through JMX. There are many ways to collect JMX metrics, but first – make sure Kafka was started with JMX_PORT environment variable set to something, so you’ll be able to collect those. I typically use JMXTrans and Graphite to collect and chart metrics. If you also use Graphite, you can start with the JMXTrans configuration I use. It’s fairly easy to collect the same metrics from any monitoring system you are used to. Whatever system you use, configure it to collect and display the important metrics described in Kafka documentation.
Next step as an admin is to observe the system under load. Apache Kafka is bundled with command line tools for generating load: bin/kafka-producer-perf-test and bin/kafka-consumer-perf-test. Explore their command line options and run them to generate some load on the system. Observe the metrics while the system is loaded. What is the maximum throughput you can drive? Can you tell where is the bottleneck?
This will also be a good time to check the Kafka app logs. By default, they are under log/ or under /var/log — depending on how you installed Kafka. Make sure the server.log has messages in it and check that there were no errors. If you see errors that you don’t understand the Apache Kafka mailing lists or StackOverflow are good resources to learn more.
Now that we know what Kafka normally looks like, let’s create some emergencies! Stop one of the brokers and look at the metrics – you should be able to see leader count drop and then recover, leader election counter climb by and the under-replicated partition count go up because of the replicas that are on the stopped broker.
Now start that broker – a few seconds later you should see more leader elections take place and the under-replicated partition count drop as the replicas on the broker catch up.
You can look at the broker logs at the broker you stopped and on other brokers – the broker you stopped should show the shutdown and startup messages. Other brokers will show messages indicating that leaders are being elected to replace those that were on the stopped broker.
I recommend spending some time stopping and starting (and hard-crashing) brokers while the performance producer and consumer are running. Review the logs and metrics to familiarize yourself with what the typical errors look like and try to track the recovery process in the log.
The last important step for an SRE is to learn the Kafka administration tools. Few suggestions:
- Use kafka-topics.sh to modify number of partitions, replication factor and even place new partitions and replicas on specific brokers.
- Use kafka-topics.sh to delete a topic
- Use kafka-config.sh to modify topic configuration — for example, the retention period for a topic
- Often application developers ask SREs to help them troubleshoot consumers who are lagging or not making progress. Or even ask the SREs to actively monitor consumers for lag. While a system like Confluent Control Center is better for ongoing monitoring, you can use the CLI tools bin/kafka-consumer-groups.sh to discover consumer groups and check their lag.
- Use bin/kafka-reassign-partitions.sh to move partitions and replicas from one broker to another.
- If you installed the Confluent Kafka packages, you can also use Confluent Rebalancer to check the load on each broker and move partitions around automatically to balance things out.
ETL Engineer / Data Warehouse Engineer
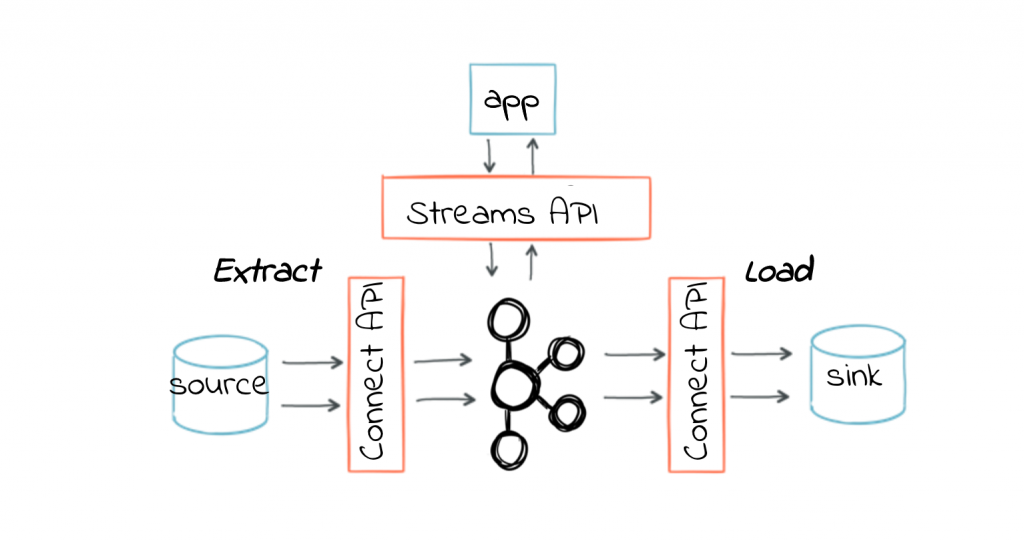 As an ETL or DWH engineer, you mostly care about getting data from here to there reliably, and when possible with the schema intact.
As an ETL or DWH engineer, you mostly care about getting data from here to there reliably, and when possible with the schema intact.
You will probably want to explore enterprise data management features like Kafka Connect, Apache Kafka’s data integration tools and the Schema Registry, schema management service from Confluent.
Kafka Connect is part of Apache Kafka, so no matter how you installed Kafka, you have it ready. The first step would be to just try running Kafka Connect in either stand-alone or distributed mode and stream a file or two to and from Kafka — you do this by following step 7 of the Kafka quickstart guide — which uses a stand-alone connector to stream data from and to a file.
That’s fun, but we are not here to stream files — we are here to integrate REAL data stores.
Let’s install the Schema Registry since some Kafka connectors depend on it. If you installed Apache Kafka and not Confluent, you will want to either download Confluent installation which contains the Schema Registry, or you can build it from sources on Github.
The schema registry assumes that data written in and out of Kafka is not just text or JSON, but Avro files and contain a schema. When producers write data to Kafka, the schema of the data is stored in the registry and it validates that the data is compatible with existing schemas. Consumers use the schemas in the registry to be able to work with older and newer versions of the data in a compatible manner. This also allows users to explore and discover which data is associated with which topic.
If you prefer not to install a schema registry, no worries! Most Connectors will still work, but you just need to make sure that when configuring Connect, you set the converters to convert data to JSON and not Avro by using:
key.converter=org.apache.kafka.connect.json.JsonConverter value.converter=org.apache.kafka.connect.json.JsonConverter
Let’s assume you want to stream data from MySQL and to ElasticSearch. Confluent packages include a JDBC Connector and an ElasticSearch Connector that you can use or you can build them from the sources on github. Once you have the connectors, you can follow the quickstart guides for JDBC Source and ElasticSearch Sink to stream events through Kafka.
Finally, you can explore Confluent Control Center, which allows you to both configure connectors and to monitor the stream of data from source to sinks and from producers to consumers.
Where to go next?
Hopefully, this guide walked you through your first days with Kafka and your first cool POC. I hope you did something cool that you can show off to your team and your managers — created a first Kafka application; configured, monitored and validated a 3-node Kafka cluster, or built a simple ETL pipeline.
You probably want to continue reading the Kafka documentation to learn more about how Kafka works and best practices of using it. Perhaps you should attend a conference to hear how others are using Kafka. You may want to read additional posts on this blog and learn more about specific Kafka features. You can read this “oldie but goodie” tutorial by Michael Noll and learn more about Kappa architecture — one of the best Kafka use cases. You can find more useful talks and webinars on our resources page. There’s also a comprehensive Kafka book that you can use as a reference.
If you are very serious about learning Kafka, you probably want to take Apache Kafka training with an instructor. This allows you to spend time diving more deeply into the system and experiment — with a guide available for questions and to bail you out when things go wrong.
And last but not least, join us for Kafka Summit, the only conference dedicated to Apache Kafka and stream processing technologies. We’ll have great content from companies who use Kafka and are happy to share their architectures, best practices, problems, and solutions. Kafka Summit will take place in New York on May 8th and San Francisco on August 28th.
Get started with Confluent, for free
Watch demo: Kafka streaming in 10 minutes
Avez-vous aimé cet article de blog ? Partagez-le !
Abonnez-vous au blog Confluent



Kafka-docker-composer: A Simple Tool to Create a docker-compose.yml File for Failover Testing
The Kafka-Docker-composer is a simple tool to create a docker-compose.yml file for failover testing, to understand cluster settings like Kraft, and for the development of applications and connectors.


How to Process GitHub Data with Kafka Streams
Learn how to track events in a large codebase, GitHub in this example, using Apache Kafka and Kafka Streams.